Gilles Civario and Michael Lysaght from ICHEC show how to take advantage of the OpenMP 4.0 standard on Xeon and Intel Xeon Phi coprocessors to portably and efficiently maximize an N-body kernel on the entire available hardware. The chapter authors point out that the sample code can be used as a template applicable for countless of real live codes. By adapting this template to their algorithm, scientists and code developers alike will unleash the full potential of the hardware they have access to in a very simple and straightforward manner.

A simple and portable method is introduced to dynamically balance workload between all the computing resources available on a heterogeneous platform, including the Intel Xeon Phi coprocessors. Speed-ups of up to 4x in single precision and 6.5x in double precision, relative to using the two conventional Xeon processors on their own. Moreover, the method, using only a handful of standard OpenMP 4.0 features throughout, is perfectly portable and future proof. It should be emphasized that the dynamic load-balancing method we described here can be trivially adapted to all sorts of computational problems where the Intel Xeon Phi coprocessor can be exploited, which should make it of interest to a wide community of developers.
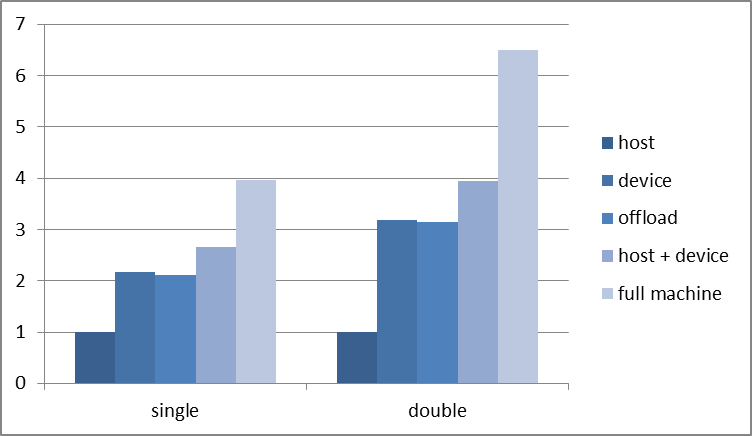
Speed‐up (in single and double precision) of several versions of an N-Body code relative to two Xeon E5‐2660 v2 Ivy Bridge processors (higher is better). (courtesy Morgan Kaufmann)
Chapter Authors

Gilles Civario
Gilles Civario joined ICHEC in June 2008 where he is now a Senior Software Architect. His main role is to design and implement tailored hardware and software solutions to users of the National Service and to ICHEC’s technology transfer client companies. Gilles is also involved in the broader aspects of the Centre’s mission where his expertise is valuable in areas such as code installation, debugging or optimisation and hardware evaluation. He is also particularly involved all aspects related to novel architectures and their programming languages. As such Gilles has gained a wide recognition from industry developers and users alike, for driving forward the development of novel architectures, such as NVIDIA CUDA-enabled GPUs and Intel Xeon Phi coprocessors. Gilles holds two Master degrees in Scientific Computing and Applied Mathematics from the University of Franche Conté, France.

Michael Lysaght
Michael Lysaght leads the Novel Technologies Activity and the Intel Parallel Computing Centre at the Irish Centre for High End Computing (ICHEC), where he has a particular focus on supporting the Irish scientific user community and Irish industry in the exploitation of emerging multi-/many- core technologies. In conjunction with his role at ICHEC, Michael also leads the WP7 ‘Exploitation of HPC Tools and Techniques’ activity as part of the EU’s PRACE 3IP project. Michael joined ICHEC in 2011 after working in the UK as a HPC application expert as part of HECToR’s distributed Computational Science and Engineering program, where he worked on re-factoring and optimising community codes for the UK research community. Prior to this he worked for three years as a UK EPSRC Postdoctoral Research Fellow in theoretical atomic physics at Queen’s University Belfast, where he pioneered the development of Time-Dependent R-Matrix Theory and associated parallel applications including the TDRM and RMT codes. Michael obtained his PhD in physics in 2006 from University College Dublin.
Click to see the overview article “Teaching The World About Intel Xeon Phi” that contains a list of TechEnablement links about why each chapter is considered a “Parallelism Pearl” plus information about James Reinders and Jim Jeffers, the editors of High Performance Parallelism Pearls.
Leave a Reply