
Nvidia announced new Quadro cards that deliver an enterprise-grade visual computing platform with up to twice the application performance and data-handling capability of the previous generation. The new generation of Quadro GPUs -- the K5200, K4200, K2200, K620 and K420 -- enables users to: Interact with data sets or designs up to twice the size handled by previous … [Read more...]
Metagenomic Sequence Clustering using CUDA-enabled GPUs

There have been huge advances in DNA sequencing technologies in recent years; e.g. Illumina has just announced the HiSeq X system which can sequence human genomes at a cost of only $1000 per genome. Besides population-scale human genome sequencing another important application of sequencing technologies is environmental sequencing (so called metagenomics). Metagenomic studies … [Read more...]
Nvidia Talks About ARM64 and 64-bit K1 SoC

The Hot Chips 2014 conference conveyed some hot information this week about Nvidia's 64-bit Tegra K1 -the first 64-bit ARM processor for Android devices that pairs the dual-core "Project Denver" CPU with Nvidia's 192-core Kepler GPU (a ceepee geepee). The ARM-based Denver CPU was custom designed by Nvidia and is compatible with ARM's 64-bit ARMv8-A architecture. The chip is … [Read more...]
Accelerating the Traveling Salesman Problem with GPUs and Intel Xeon Phi
The traveling salesman problem (TSP) is an important computer science optimization problem with numerous real-world applications. There is a huge body of literature on TSP solutions. Following are a few GPU and Intel Xeon Phi accelerated solutions. TSPgpu TSPGPU v2.1 is a GPU-accelerated heuristic solver for the symmetric Traveling Salesman Problem with up to 32767 … [Read more...]
Depth-Categorizing GPU-Accelerated Deep Neural Networks Perform Fast Semantic Segmentation of RGB-D Scenes

Interesting for computer vision and animation, the paper by Nico Höft, Hannes Schulz, and Sven Behnke, "Fast Semantic Segmentation of RGB-D Scenes with GPU-Accelerated Deep Neural Networks" categorizes the surface to which each pixel in an image belongs. Semantic scene segmentation is a major challenge on the way to functional computer vision systems that can separately label … [Read more...]
WRF Comparison – Neither Phi or NVIDIA M2070 Living Up to Name
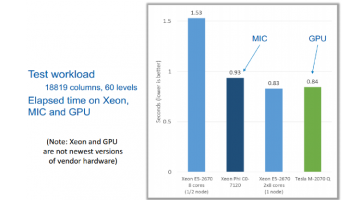
WRF (Weather Research and Forecasting) is an important benchmark for weather modeling, computational scientists, and procurements. WRF is a mesoscale numerical weather prediction system designed to serve both atmospheric research and operational forecasting needs. It allows researchers to generate atmospheric simulations based on real data (observations, analyses) or … [Read more...]
Paper Compares AMD, NVIDIA, Intel Xeon Phi CFD Turbulent Flow Mesh Performance Using OpenMP and OpenCL

Timely for Siggraph 2014 (because animations use meshes) and food-for-thought for CFD (Computational Fluid Dynamics) research, the paper by A. Gorobets, F.X. Trias, R. Borrell, G. Oyarzún and A. Oliva, "Direct Numerical Simulation of Turbulent Flows with Parallel Algorithms for Various Computing Architectures" considers structured and unstructured meshes for incompressible … [Read more...]
Breadth-First Graph Search Uses 2D Domain Decomposition – 400 GTEPS on 4096 GPUs
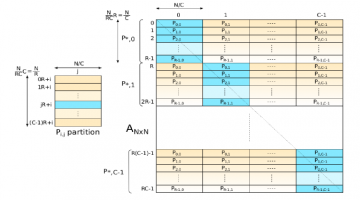
Parallel Breadth-First Search is a standard benchmark and the basis of many other graph algorithms. The challenge lies in partitioning the graph across multiple nodes in a cluster while avoiding load-imbalance and communications delays. The authors of the paper, "Parallel Breadth First Search on the Kepler Architecture" utilize an interesting 2D decomposition of the graph … [Read more...]
SC14 – Fast Hybrid GPU Betweenness Centrality Code Achieves Nearly Ideal Scaling to 192 GPUs

Don't miss the SC14 presentation Wednesday Nov. 19 in room 388-89-90, for the presentation of the McLaughlin and Bader paper "Scalable and High Performance Betweenness Centrality on the GPU". The authors report nearly ideal scaling to 192 GPUs and billions of edges traversed per step (GTEP). The paper can be downloaded here and their software can be downloaded from … [Read more...]
Tegra K1 Drives Audi A7 In Florida Driverless Car Highway Test
Audi tested a fully equipped driverless A7 on a Florida highway at speeds up to 25 miles per hour. Governor Rick Scott, a proponent of driverless vehicles and signer of the bill that allows for testing such vehicles in the state, sat in the driver's seat without touching the controls for part of the test. Audi requested a shutdown of Tampa's Lee Roy Selmon … [Read more...]