
Part 1 in this tutorial series showed that task-based parallelism using concurrent kernels can accelerate applications simply by plugging more GPUs into a system - just as the GPU strong scaling execution model can accelerate applications simply by installing a newer GPU containing more SMX (Streaming Multiprocessors). No recompilation required! NVIDIA nvvp timelines show very … [Read more...]
Part 1: Load-Balanced, Strong-Scaling Task-Based Parallelism on GPUs

Achieve a 7.4x speedup with 8 GPUs over the performance of a single GPU through the use of task-based parallelism and concurrent kernels! Traditional GPU programming typically views the GPU as a monolithic device that runs a single parallel kernel across the entire device. This approach is fantastic when one kernel can provide enough work to keep the GPU busy. The conundrum is … [Read more...]
Combine C-Sharp With CUDA and OpenCL On Linux, iOS, Android and Windows

Google Protobufs (via protobuf-net) in combination with the click-together framework taught in my CUDA and OpenCL tutorials allows C# and .NET programmers to include Linux and Windows GPU and Intel Xeon Phi codes in their workflows. Mono The freely available opensource mono-project creates C# executables that can run unchanged on both Linux and Windows - just copy the … [Read more...]
Pragma Puzzler – Ambiguous Loop Trip Count in OpenMP and OpenACC

Pragma-based programming can be described as a "negotiation" with the compiler where the compiler has to assume corner-cases that are not apparent to the programmer. So why does the loop count in the OpenMP and OpenACC article, "A First Transparent OpenACC C++ Class" have to be assigned to a separate variable to generate a parallel … [Read more...]
A First Transparent OpenACC C++ Class
This article provides a simple yet complete working example that demonstrates how OpenACC 2.0 pragmas can be used in the constructor and destructor of a C++ class to allocate and free memory on both the host and device and to transparently move data in the C++ class to support C++ class methods that run on both the host and device. Key to the transparent use of C++ classes in … [Read more...]
MultiOS Gaming CUDA & OpenCL Via a Virtual Machine

Update 12/1/14: Intel now offers through the Xen project full GPU virtualization for Intel 4th generation devices. Operating system virtualization is a convenient way to run multiple operating systems at the same time, on the same hardware, without requiring rebooting. There are several technologies that allow sharing of the GPU by both the host (native) and guest … [Read more...]
ExaFMM: An Exascale-capable, TF/s per GPU or Xeon Phi, Long-Range Force Library for Particle Simulations

Rio Yokota has implemented exaFMM, a Fast Multipole Method library to speed applications that must quickly calculate the effects of long-range forces such as gravity or magnetism on discrete particles in a simulation. Based on work he performed as a post-doc with Lorena Barba, the open-source FMM library runs on GPUs, multicore, and Intel Xeon Phi plus most of the … [Read more...]
GaussianFace: Computers Claimed to Beat Humans in Recognizing Faces
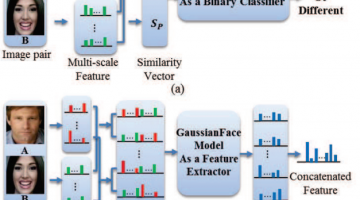
In a human vs. computer test on 13k photos of 6k public figures, the GaussianFace project claims to identify human faces better than humans (97% human accuracy vs. 98% computer accuracy). The authors claim their model can adapt automatically to complex data distributions, and therefore can well capture complex face variations inherent in multiple sources. The reporters at The … [Read more...]
Inside NVIDIA’s Unified Memory: Multi-GPU Limitations and the Need for a cudaMadvise API Call

The CUDA 6.0 Unified Memory offers a “single-pointer-to-data” model that is similar to CUDA’s zero-copy mapped memory. Both make it trivially easy for the programmer to access memory on the CPU or GPU, but applications that use mapped memory have to perform a PCI bus transfer occur every time a memory access steps outside of a cache line while a kernel running in a Unified … [Read more...]
Intel Xeon Phi for CUDA Programmers
Both GPU and Xeon Phi coprocessors provide high degrees of parallelism that can deliver excellent application performance. For the most part, CUDA programmers with existing application code have already written their software so it can run well on Phi coprocessors. The key to performance lies in understanding the differences between these two architectures. Author's note: To … [Read more...]