
Reaching one teraflop on Intel's new 60-core coprocessor requires a little know-how First printed December 10, 2012 on Dr. Dobbs ( link ) Developers can reach a teraflop/s of number crunching power via one of several routes: Using pragmas to augment existing codes so they offload work from the host processor to the Intel Xeon Phi coprocessors(s) Recompiling source … [Read more...]
Part 1: OpenCL™ – Portable Parallelism
This first article in a series on portable multithreaded programming using OpenCL™ briefly discusses the thought behind the standard and demonstrates how to download and use the ATI Stream software development kit (SDK) to build and run an OpenCL program. view at The Code Project (http://www.codeproject.com/Articles/110685/Part-OpenCL-Portable-Parallelism) The thought … [Read more...]
Pragmatic Parallelism Part 1: Introducing OpenACC 1.0
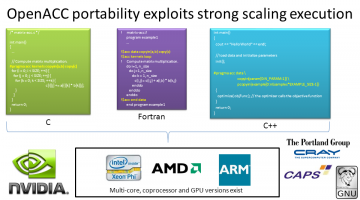
OpenACC lets you program in parallel C/C++ and Fortran in a manner that is concise and where the same source code can be recompiled to run on AMD GPUs, NVIDIA GPUs, Intel Xeon Phi, x86, and ARM. View at Dr. Dobbs (http://www.drdobbs.com/parallel/easy-gpu-parallelism-with-openacc/240001776) This is the first in a series of articles by Rob Farber on OpenACC directives, … [Read more...]
Part 3 of CUDA Supercomputing for the masses
Error handling and global memory performance limitations. This article is reprinted from Dr. Dobbs (http://www.ddj.com/hpc-high-performance-computing/207603131). It is still valid as an introductory article. Congratulations! Thanks to Part 1 and Part 2 of this series on CUDA (short for "Compute Unified Device Architecture"), you are now a CUDA-enabled programmer with the … [Read more...]
Part 2 of CUDA Supercomputing for the Masses

A first CUDA kernel. Reprinted from Dr. Dobbs April 29, 2008 (link) Comment: This article is still valid as it shows how to write a simple code to move data to/from the GPU and operate on it with a CUDA kernel. In Part 1 of this article series, I presented a simple first CUDA (short for "Compute Unified Device Architecture") program called moveArrays.cu to familiarize … [Read more...]