
Update 12/1/14: Intel now offers through the Xen project full GPU virtualization for Intel 4th generation devices. Operating system virtualization is a convenient way to run multiple operating systems at the same time, on the same hardware, without requiring rebooting. There are several technologies that allow sharing of the GPU by both the host (native) and guest … [Read more...]
May 2014 Current K1 Development Pathways

NVIDIA Tegra K1 Jetson development kits are now available for purchase from Newegg or Microcenter. The NVIDIA Tegra K1 chip has generated much interest due to the CUDA programmability and power efficiency of the ARM/Kepler ceepee-geepee combination. Upcoming Tegra K1 devices include the Xiaomi MiPad, NVIDIA's reference design tablet, plus the K1 powered Shield 2 gaming device. … [Read more...]
The CUDA Thrust API Now Supports Streams and Concurrent Tasks

The CUDA Thrust API now supports streams and concurrent kernels through the use of a new API called Bulk created by Jared Hoberock at NVIDIA. The design of Bulk is intended to extend the parallel execution policies described in the evolving Technical Specification for Parallel Extensions for C++ N3960. Note that bulk is not part of the CUDA 6.0 distribution and must be … [Read more...]
OpenCL + Java Acceleration on Mobile Promises 8x speedup with 3x Less Power

In what will certainly become a flood of papers about GPU acceleration of Java applications on mobile devices, a masters theses by Iype P. Joseph at the University of Ottawa claims 8x performance gains and 3x reductions in power consumption through the use of Java binding with OpenCL 1.1 on a a Freescale i.MX6Q SabreLite board. With NVIDIA entering the programmable mobile GPU … [Read more...]
ExaFMM: An Exascale-capable, TF/s per GPU or Xeon Phi, Long-Range Force Library for Particle Simulations

Rio Yokota has implemented exaFMM, a Fast Multipole Method library to speed applications that must quickly calculate the effects of long-range forces such as gravity or magnetism on discrete particles in a simulation. Based on work he performed as a post-doc with Lorena Barba, the open-source FMM library runs on GPUs, multicore, and Intel Xeon Phi plus most of the … [Read more...]
Opportunities to Run on Jetson, the Latest Tegras, and ORNL Titan

Following Jen-Hsun's strategy to enable those who wish to use NVIDIA chips, developers can win a Jetson K1, get free access to the latest Tegra GPUs. Also those with big computations can submit INCITE proposals to run on the ORNL Titan supercomputer. Ends today (4/30/14) to possibly win a Jetson K1 (link) merely by submitting an idea via … [Read more...]
GaussianFace: Computers Claimed to Beat Humans in Recognizing Faces
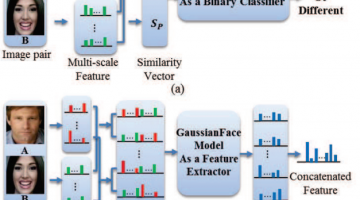
In a human vs. computer test on 13k photos of 6k public figures, the GaussianFace project claims to identify human faces better than humans (97% human accuracy vs. 98% computer accuracy). The authors claim their model can adapt automatically to complex data distributions, and therefore can well capture complex face variations inherent in multiple sources. The reporters at The … [Read more...]
Run CUDA without Recompilation on x86, AMD GPUs, and Intel Xeon Phi with gpuOcelot
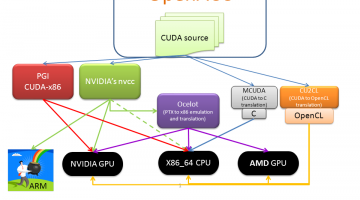
Various pathways exist to run CUDA on a variety of different architectures. The freely available gpuOcelot project is unique in that it currently allows CUDA binaries to run on NVIDIA GPUs, AMD GPUs, x86 and Intel Xeon Phi at full speed without recompilation. It works by dynamically analyzing and recompiling the PTX instructions of the CUDA kernels so they can run on the … [Read more...]
K1-powered NVIDIA Shield 2 Benchmarks Appear

The good folks at Tom's Hardware are lending credibility to the Antutu benchmarks of a K1 powered NVIDIA Shield 2 (link). It is not surprising that the NVIDIA Shield would be one of the first platforms to contain the newest NVIDIA Tegra chip. The claimed specs for the Shield-2 appear reasonable: A screen resolution of 1440 x 810, 4 GB of RAM 16 GB of internal … [Read more...]
Inside NVIDIA’s Unified Memory: Multi-GPU Limitations and the Need for a cudaMadvise API Call

The CUDA 6.0 Unified Memory offers a “single-pointer-to-data” model that is similar to CUDA’s zero-copy mapped memory. Both make it trivially easy for the programmer to access memory on the CPU or GPU, but applications that use mapped memory have to perform a PCI bus transfer occur every time a memory access steps outside of a cache line while a kernel running in a Unified … [Read more...]