
GTC 2014 demonstrated that we have now entered the "Battery Powered Supercomputing for the Masses" era. I had the opportunity to experience a Jetson TK1 board running ubuntu 13.04 at the hands-on lab. First impressions were very positive with a snappy response to the Ubuntu window system.. The GTC hands-on labs are oriented for techies and not the press. They provide a very … [Read more...]
Deep-learning Teaching Code Achieves 13 PF/s on the ORNL Titan Supercomputer
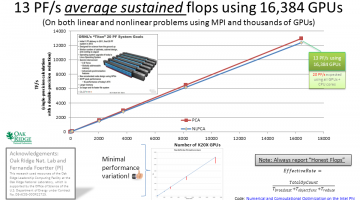
The deep-learning teaching code described in my book, "CUDA Application Design and Development" [Chapters 2, 3, and 9] plus online tutorials achieved 13 PF/s average sustained performance using 16,384 GPUs on the Oakridge Titan supercomputer. Full source code for my teaching code can be found on github in the farbopt directory. Nicole Hemsoth at HPCwire noted these CUDA … [Read more...]
TechEnablement Adds Study Guides for CUDA, OpenACC, OpenCL, and Intel Xeon Phi
Today techEnablement.com has provided study guides to help students "learn to change the world" with supercomputing for the masses . The study guides cover: CUDA OpenACC OpenCL Intel Xeon Phi … [Read more...]
Intel Xeon Phi for CUDA Programmers
Both GPU and Xeon Phi coprocessors provide high degrees of parallelism that can deliver excellent application performance. For the most part, CUDA programmers with existing application code have already written their software so it can run well on Phi coprocessors. The key to performance lies in understanding the differences between these two architectures. Author's note: To … [Read more...]
CUDA 6.0 Released

The CUDA 6 Production Release is now available for download at www.nvidia.com/getcuda. This version of the toolkit includes features that further simplify parallel programming like: • Unified Memory: simplifies programming by enabling applications to access the CPU and GPU memory without the need to manually copy data. • Drop-in Libraries: automatically accelerate … [Read more...]
Part 3 of CUDA Supercomputing for the masses
Error handling and global memory performance limitations. This article is reprinted from Dr. Dobbs (http://www.ddj.com/hpc-high-performance-computing/207603131). It is still valid as an introductory article. Congratulations! Thanks to Part 1 and Part 2 of this series on CUDA (short for "Compute Unified Device Architecture"), you are now a CUDA-enabled programmer with the … [Read more...]
Farber teaches massively parallel computing to grade 6 – 12 students in Saudi Arabia

My book, “CUDA Application Design and Development” [English][Chinese] and Doctor Dobbs tutorials coupled with the rapid adoption of GPU computing have given me the opportunity to speak and teach around the world. This January, I had the pleasure of traveling to Jeddah, Saudi Arabia to speak and teach a short course on OpenACC and CUDA at KAUST (the King Abdullah University of … [Read more...]