
Antonio Valles and Weiqun Zhang note the optimizations discussed in their High Performance Parallelism Pearls chapter that, "significantly improved concurrency on both Intel Xeon Phi coprocessors and Intel Xeon processors" by transforming a fine-grain thread parallel approach to a more coarse-grain, memory allocation considerate approach plus improving vectorization. They … [Read more...]
Microsoft Roomalive Creates Augmented Reality Room At Home
Ditch the AR goggles! In their paper, "RoomAlive: Magical Experiences Enabled by Scalable, Adaptive Projector-Camera Units" Microsoft researchers discuss a proof-of-concept prototype that transforms any room into an immersive, augmented entertainment experience. The basic building blocks are projector-depth camera units that create a unified model of the room with no … [Read more...]
NASA Charts Path For CFD To 2030 – Projects Future Computer Technology!
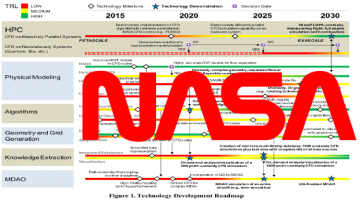
The recent NASA-sponsored report CFD Vision 2030 Study: A Path to Revolutionary Computational Aerosciences is a must-read for everyone involved in Computational Fluid Dynamics and a very interesting read for those involved in computer technology. In a nutshell, “A single engineer/scientist must be able to conceive, create, analyze, and interpret a large ensemble of related … [Read more...]
Better Concurrency and SIMD On The HIROMB‐BOOS‐Model (HBM) 3D Ocean Code

By utilizing the strengths of the Intel Xeon Phi coprocessor, the chapter 3 High Performance Parallelism Pearls authors were able to improve and modernize their code and "achieve great scaling, vectorization, bandwidth utilization and performance/watt". The authors (Jacob Weismann Poulsen, Karthik Raman and Per Berg) note, "The thinking process and techniques used in this … [Read more...]
Moving Brain Models Beyond Mother Nature For Robotic Navigation
In an attempt to create a super-navigation system, Queensland University of Technology research Dr.Michael Milford is combining human vision and rat spatial recognition computer models to solve the problem of place recognition far better than the solutions evolved by Mother Nature. Advances in computational technology coupled with the proliferation of autonomous … [Read more...]
From ‘Correct’ to ‘Correct & Efficient’: a Hydro2D case study with Godunov’s scheme

Poetically noting that "a rising tide lifts all boats", authors Guillaume Colin de Verdière and Jason D. Sewall demonstrate a 12x increase on Intel Xeon Phi and over 5x increase on Intel Xeon using, "a common set of optimizations [that] benefit both general-purpose Xeon processors and more specialized Xeon Phi accelerators" in chapter 2 of High Performance Parallelism … [Read more...]
The Unabridged Chapter 1 Introduction To High Performance Parallelism Pearls

Following is the full, unabridged text of the chapter 1 introduction (written by James Reinders) to High Performance Parallelism Pearls. Thanks to Morgan Kaufmann, James Reinders, and Jim Jeffers for giving permission so TechEnablment can make this available. After reading what James wrote, you will see that summarizing the introduction would simply have left out too much … [Read more...]
Teaching The World About Intel Xeon Phi

The newest book by James Reinders and Jim Jeffers, “High Performance Parallelism Pearls” distills the experience of sixty-nine HPC experts into twenty-eight chapters designed to teach the world about the performance capabilities of the massively-parallel Intel® Xeon Phi™ family of products. Source code for numerous working examples selected for their educational content, … [Read more...]
Analysis of Phylogenetic Tree Code Shows OpenACC Within 10% Of Native CUDA
The paper, "Accelerating Phylogenetic Inference on GPUs: an OpenACC and CUDA comparison" by University of Barcelona and Intel Barcelona Research Center claim near-CUDA performance for OpenACC - within 10% - that can be achieved when accelerating a Phylogenetic Tree code based on the popular MrBayes Markov chain Monte Carlo (MCMC) package. Comparing with state-of-art … [Read more...]
MSI WS60 Mobile Workstation – Awesome CUDA-Capable, Linux, and Window Mobility

The recently released MSI mobile workstation (WS60 20 OJ 3K-004US) provides a no-compromise laptop for those who wish a thin-and-light desktop replacement at work and when traveling. This device is now my work machine of choice (that relegated a wonderful HP Z800 workstation to a remotely accessed resource). I have found that the WS60 provides a well-designed and … [Read more...]