This chapter describes the performance of NWChem’s CCSD(T) method running on a large-scale hybrid cluster of 460 dual-socket Xeon E5-2600 series nodes each of which is equipped with two Intel Xeon Phi 5110P coprocessor cards (a total of 62.5k hybrid cores). The chapter authors describe how, without any low-level programming, offload transfers and compute kernels have been optimized. NWChem shows that high-level Fortran code can be brought to Intel Xeon Phi at high productivity while maintaining high performance and scalability.
The Intel Xeon Phi version of the code is available in NWChem version 6.5, can be obtained from the NWChem Subversion repository at https://svn.pnl.gov/svn/nwchem/trunk scheduled for release in Q3’14.

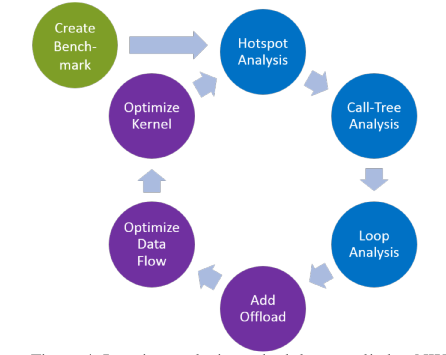
Iterative analysis methodology applied to NWChem (Figure courtesy Morgan Kaufmann)

Result of the VTune Amplifier XE Hotspot analysis for NWChem’s CCSD(T) method. (Figure courtesy Morgan Kaufmann)

Wall time to solution (in seconds) for the perturbative triples correction to the CCSD(T) corre-
lation energy of the pentacene molecule (C 22 H 14 ). A logarithmic scale is used on all the axis. (Figure courtesy Morgan Kaufmann)
Chapter Authors

Edoardo Aprà
Edoardo Aprà is a Chief Scientist at the Environmental Molecular Sciences Laboratory, part of the Pacific Northwest National Laboratory in Richland, USA. He obtained his M.Sc. and PhD in Chemistry from the University of Torino, Italy. His research activity has been focused on activities related to high-performance computational algorithm and software development as well as the use of this software in chemical applications. He is the main developer of the molecular density functional theory (DFT) module in the NWChem package.

Jeff Hammond
Jeff Hammond is a Research Scientist in the Parallel Computing Lab at Intel Labs. His research interests include: one-sided and global view programming models, load-balancing for irregular algorithms, and shared- and distributed-memory tensor contractions. He has a long-standing interest in enabling the simulation of physical phenomena—primarily the behavior of molecules and materials at atomistic resolutionwith massively parallel computing. Jeff received his PhD in chemistry from the University of Chicago as a Department of Energy Computational Science Graduate Fellow; his dissertation research on coupled cluster response theory was supervised by Karol Kowalski.

Michael Klemm
Dr. Michael Klemm is part of Intel’s Software and Services Group, Developer Relations Division. His focus is on High Performance and Throughput Computing. He obtained an M.Sc. in Computer Science and a Doctor of Engineering degree (Dr.-Ing.) in Computer Science from the Friedrich-Alexander-Universität Erlangen-Nürnberg. Michael’s areas of interest includes compiler construction, design of programming languages, parallel programming, and performance analysis and tuning. Michael is Intel representative in the OpenMP Language Committee and leads the efforts to develop error handling features for OpenMP. He is also co-author of the chapter “Concurrent Kernel Offloading On Intel Xeon Phi“

Karol Kowalski
Karol Kowalski is a Chief Scientist at the Environmental Molecular Sciences Laboratory, part of the Pacific Northwest National Laboratory in Richland, USA. He obtained a PhD in Physics from the Nicolaus Copernicus University, Poland. His research focuses on the development of accurate electronic structure methods and their highly scalable implementations. The methods developed by Dr. Kowalski have been applied to describe a wide spectrum of many-body systems ranging from nuclei and molecules, to the systems being at the cross-road between molecular- and nano-science.
Leave a Reply