
Directive-based compilers offer both portability and the ability to optimized code for specific platforms such as GPUs and CPUs. A recent LCPC14 paper, "Directive-Based Compilers for GPUs", by Swapnil Ghike, Ruben Gran, Maria J. Garzaran, David Padua at the University of Illinois at Urbana-Champaign found OpenACC code generated by the PGI and Cray OpenACC compilers achieved … [Read more...]
CUDA 340.29 Driver Significantly Boosts GPU Performance (100s GF/s For Machine-Learning)
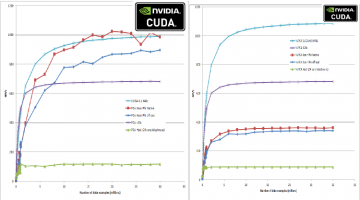
Reports are now coming in about performance boosts that are the result of the CUDA 6.5 production release. The Blender project reports faster rendering time with CUDA-6.5. As can be seen in the graphs below that report performance on the farbopt deep-learning teaching code, CUDA-6.5 with the NVIDIA 340.29 driver have increased performance on linear problems (PCA analysis from … [Read more...]
PyFR: A GPU-Accelerated Next-Generation Computational Fluid Dynamics Python Framework

PyFR is an open-source 5,000 line Python based framework for solving fluid-flow problems that can exploit many-core computing hardware such as GPUs! Computational simulation of fluid flow, often referred to as Computational Fluid Dynamics (CFD), plays an critical role in the aerodynamic design of numerous complex systems, including aircraft, F1 racing cars, and wind turbines. … [Read more...]
Berkeley Online and Onsite 2014 Short Course on Parallel Programming – Aug. 18

Monday August 18, 2014 the Berkeley EECS ( Electrical Engineering and Computer Sciences, COLLEGE OF ENGINEERING, UC Berkeley) will provide an on-site and on-line introduction to parallel architectures and programming issues, a thorough exposure to languages and tools for shared memory programming, including hands-on experience, a presentation of high level programming parallel … [Read more...]
Metagenomic Sequence Clustering using CUDA-enabled GPUs

There have been huge advances in DNA sequencing technologies in recent years; e.g. Illumina has just announced the HiSeq X system which can sequence human genomes at a cost of only $1000 per genome. Besides population-scale human genome sequencing another important application of sequencing technologies is environmental sequencing (so called metagenomics). Metagenomic studies … [Read more...]
Nvidia Talks About ARM64 and 64-bit K1 SoC

The Hot Chips 2014 conference conveyed some hot information this week about Nvidia's 64-bit Tegra K1 -the first 64-bit ARM processor for Android devices that pairs the dual-core "Project Denver" CPU with Nvidia's 192-core Kepler GPU (a ceepee geepee). The ARM-based Denver CPU was custom designed by Nvidia and is compatible with ARM's 64-bit ARMv8-A architecture. The chip is … [Read more...]
Acer K1-powered Chromebook $279 for Pre-Order – Dual-boot Linux?

The Acer Chromebook 13, priced at $279, is the first Chromebook to use an NVIDIA Tegra K1 processor. It offers customers fast graphics and a 13-hour battery in an ultra-mobile form factor. Available for presale now at Amazon.com and BestBuy.com. Spec from Amazon.com: Screen Size 13.3 inches Max Screen Resolution 1366 x 768 pixels Processor 2.1 GHz … [Read more...]
GPU Accelerated Genetic Algorithm Can Plan Drone Missions

Both the military and commercial organizations like Amazon will be interested in the GPU accelerated genetic algorithm (GA) proposed in the paper "UAV Path Planning with Parallel Genetic Algorithms on CUDA architecture" to create flight plans for drones. The authors noted "The experiments in this study show that the results reach up to 24 times speedup comparing to the CPU … [Read more...]
Accelerating the Traveling Salesman Problem with GPUs and Intel Xeon Phi
The traveling salesman problem (TSP) is an important computer science optimization problem with numerous real-world applications. There is a huge body of literature on TSP solutions. Following are a few GPU and Intel Xeon Phi accelerated solutions. TSPgpu TSPGPU v2.1 is a GPU-accelerated heuristic solver for the symmetric Traveling Salesman Problem with up to 32767 … [Read more...]
Breadth-First Graph Search Uses 2D Domain Decomposition – 400 GTEPS on 4096 GPUs
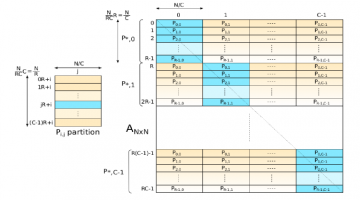
Parallel Breadth-First Search is a standard benchmark and the basis of many other graph algorithms. The challenge lies in partitioning the graph across multiple nodes in a cluster while avoiding load-imbalance and communications delays. The authors of the paper, "Parallel Breadth First Search on the Kepler Architecture" utilize an interesting 2D decomposition of the graph … [Read more...]