The paper, "Accelerating Phylogenetic Inference on GPUs: an OpenACC and CUDA comparison" by University of Barcelona and Intel Barcelona Research Center claim near-CUDA performance for OpenACC - within 10% - that can be achieved when accelerating a Phylogenetic Tree code based on the popular MrBayes Markov chain Monte Carlo (MCMC) package. Comparing with state-of-art … [Read more...]
MSI WS60 Mobile Workstation – Awesome CUDA-Capable, Linux, and Window Mobility

The recently released MSI mobile workstation (WS60 20 OJ 3K-004US) provides a no-compromise laptop for those who wish a thin-and-light desktop replacement at work and when traveling. This device is now my work machine of choice (that relegated a wonderful HP Z800 workstation to a remotely accessed resource). I have found that the WS60 provides a well-designed and … [Read more...]
GPUs Power Over 90% of ImageNet Deep-Learning Visual Recognition Challenge Entries

Over 90 percent of the participating teams and three of the four winners in the prestigious 2014 ImageNet Large Scale Visual Recognition Challenge used GPUs to enable their deep learning work. Deep learning is a fast-growing segment of machine learning that involves the creation of sophisticated, multi-level or “deep” neural networks. These networks enable powerful … [Read more...]
New PyFR Paper “Heterogeneous Computing on Mixed Unstructured Grids with PyFR”

Peter Vincent's original PyFR post on TechEnablement has been extremely popular. Readers should be happy to hear that the PyFR team has published a new paper, "Heterogeneous Computing on Mixed Unstructured Grids with PyFR", showing this Python framework can perform high-order accurate unsteady simulations of flow on mixed unstructured grids using heterogeneous multi-node … [Read more...]
Dongarra Gives Deep-Learning a Python Interface With RaPyDLI

An NSF-funded project called "Rapid Python Deep Learning Infrastructure", or RaPyDLI received nearly $1 million in NSF grants. The project led by supercomputing luminaries Jack Dongarra (University of Tennessee) and Geoffrey Fox (Indiana University) along with Andrew Ng (Stanford, Baidu and Coursera) will allow users to program deep learning models in Python and port them to … [Read more...]
Funding for HPC in the Natural Sciences at Mainz University

Many branches of the natural sciences are currently in the process of transition to the use of data-driven concepts. In recognition of this, the Carl Zeiss Foundation will provide EUR 750,000 over four years to fund the Competence Center for HPC in the Natural Sciences at the Institute of Computer Science of Johannes Gutenberg University Mainz (JGU). Jointly headed by Professor … [Read more...]
OpenACC Compilers Deliver 85% The Performance Of Hand-Optimized Code

Directive-based compilers offer both portability and the ability to optimized code for specific platforms such as GPUs and CPUs. A recent LCPC14 paper, "Directive-Based Compilers for GPUs", by Swapnil Ghike, Ruben Gran, Maria J. Garzaran, David Padua at the University of Illinois at Urbana-Champaign found OpenACC code generated by the PGI and Cray OpenACC compilers achieved … [Read more...]
CUDA 340.29 Driver Significantly Boosts GPU Performance (100s GF/s For Machine-Learning)
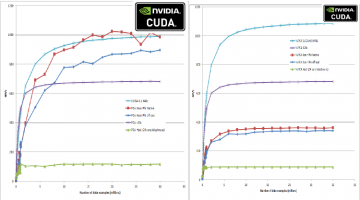
Reports are now coming in about performance boosts that are the result of the CUDA 6.5 production release. The Blender project reports faster rendering time with CUDA-6.5. As can be seen in the graphs below that report performance on the farbopt deep-learning teaching code, CUDA-6.5 with the NVIDIA 340.29 driver have increased performance on linear problems (PCA analysis from … [Read more...]
PyFR: A GPU-Accelerated Next-Generation Computational Fluid Dynamics Python Framework
PyFR is an open-source 5,000 line Python based framework for solving fluid-flow problems that can exploit many-core computing hardware such as GPUs! Computational simulation of fluid flow, often referred to as Computational Fluid Dynamics (CFD), plays an critical role in the aerodynamic design of numerous complex systems, including aircraft, F1 racing cars, and wind turbines. … [Read more...]
Berkeley Online and Onsite 2014 Short Course on Parallel Programming – Aug. 18

Monday August 18, 2014 the Berkeley EECS ( Electrical Engineering and Computer Sciences, COLLEGE OF ENGINEERING, UC Berkeley) will provide an on-site and on-line introduction to parallel architectures and programming issues, a thorough exposure to languages and tools for shared memory programming, including hands-on experience, a presentation of high level programming parallel … [Read more...]