This article provides a simple yet complete working example that demonstrates how OpenACC 2.0 pragmas can be used in the constructor and destructor of a C++ class to allocate and free memory on both the host and device and to transparently move data in the C++ class to support C++ class methods that run on both the host and device. Key to the transparent use of C++ classes in … [Read more...]
MultiOS Gaming CUDA & OpenCL Via a Virtual Machine

Update 12/1/14: Intel now offers through the Xen project full GPU virtualization for Intel 4th generation devices. Operating system virtualization is a convenient way to run multiple operating systems at the same time, on the same hardware, without requiring rebooting. There are several technologies that allow sharing of the GPU by both the host (native) and guest … [Read more...]
The CUDA Thrust API Now Supports Streams and Concurrent Tasks

The CUDA Thrust API now supports streams and concurrent kernels through the use of a new API called Bulk created by Jared Hoberock at NVIDIA. The design of Bulk is intended to extend the parallel execution policies described in the evolving Technical Specification for Parallel Extensions for C++ N3960. Note that bulk is not part of the CUDA 6.0 distribution and must be … [Read more...]
GaussianFace: Computers Claimed to Beat Humans in Recognizing Faces
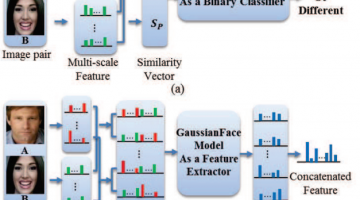
In a human vs. computer test on 13k photos of 6k public figures, the GaussianFace project claims to identify human faces better than humans (97% human accuracy vs. 98% computer accuracy). The authors claim their model can adapt automatically to complex data distributions, and therefore can well capture complex face variations inherent in multiple sources. The reporters at The … [Read more...]
Run CUDA without Recompilation on x86, AMD GPUs, and Intel Xeon Phi with gpuOcelot
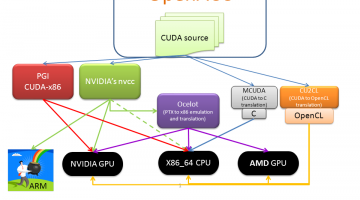
Various pathways exist to run CUDA on a variety of different architectures. The freely available gpuOcelot project is unique in that it currently allows CUDA binaries to run on NVIDIA GPUs, AMD GPUs, x86 and Intel Xeon Phi at full speed without recompilation. It works by dynamically analyzing and recompiling the PTX instructions of the CUDA kernels so they can run on the … [Read more...]
Inside NVIDIA’s Unified Memory: Multi-GPU Limitations and the Need for a cudaMadvise API Call

The CUDA 6.0 Unified Memory offers a “single-pointer-to-data” model that is similar to CUDA’s zero-copy mapped memory. Both make it trivially easy for the programmer to access memory on the CPU or GPU, but applications that use mapped memory have to perform a PCI bus transfer occur every time a memory access steps outside of a cache line while a kernel running in a Unified … [Read more...]
TechEnablement Adds Study Guides for CUDA, OpenACC, OpenCL, and Intel Xeon Phi
Today techEnablement.com has provided study guides to help students "learn to change the world" with supercomputing for the masses . The study guides cover: CUDA OpenACC OpenCL Intel Xeon Phi … [Read more...]
Intel Xeon Phi for CUDA Programmers
Both GPU and Xeon Phi coprocessors provide high degrees of parallelism that can deliver excellent application performance. For the most part, CUDA programmers with existing application code have already written their software so it can run well on Phi coprocessors. The key to performance lies in understanding the differences between these two architectures. Author's note: To … [Read more...]
Pragmatic Parallelism Part 1: Introducing OpenACC 1.0
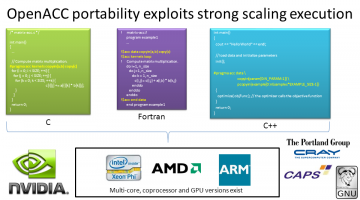
OpenACC lets you program in parallel C/C++ and Fortran in a manner that is concise and where the same source code can be recompiled to run on AMD GPUs, NVIDIA GPUs, Intel Xeon Phi, x86, and ARM. View at Dr. Dobbs (http://www.drdobbs.com/parallel/easy-gpu-parallelism-with-openacc/240001776) This is the first in a series of articles by Rob Farber on OpenACC directives, … [Read more...]
Part 3 of CUDA Supercomputing for the masses
Error handling and global memory performance limitations. This article is reprinted from Dr. Dobbs (http://www.ddj.com/hpc-high-performance-computing/207603131). It is still valid as an introductory article. Congratulations! Thanks to Part 1 and Part 2 of this series on CUDA (short for "Compute Unified Device Architecture"), you are now a CUDA-enabled programmer with the … [Read more...]