HPC storage luminary Gary Grider, noted in his talk at the SC14 Seagate HPC User Group meeting, “The Future of Supercomputing” that he funded the development of the Lustre file-system (which can stream a data at a TB/s), and he believes it is possible we will see the end of such file-systems before he reaches retirement age. Instead, Gary sees object based storage similar to Dropbox becoming the standard model for HPC. Such development also heralds the end of RAID (Redundant Arrays of Individual Disks) because of the potentially large amount of time required to rebuild the storage system after a failure. In effect, “change the POSIX file system semantics“, and “dare to let the storage system fail“.
Gary’s paper, “Preparing Applications for Next Generation IO/Storage“, outlines the reasons for such a radical departure from current storage models. In short, he views the following as the drivers behind this change in HPC storage:
- Scale
- Machine size (massive failure)
- Storage size (must face failure)
- Size of data/number of objects
- Bursty behavior
- Technology Trends
- Economics
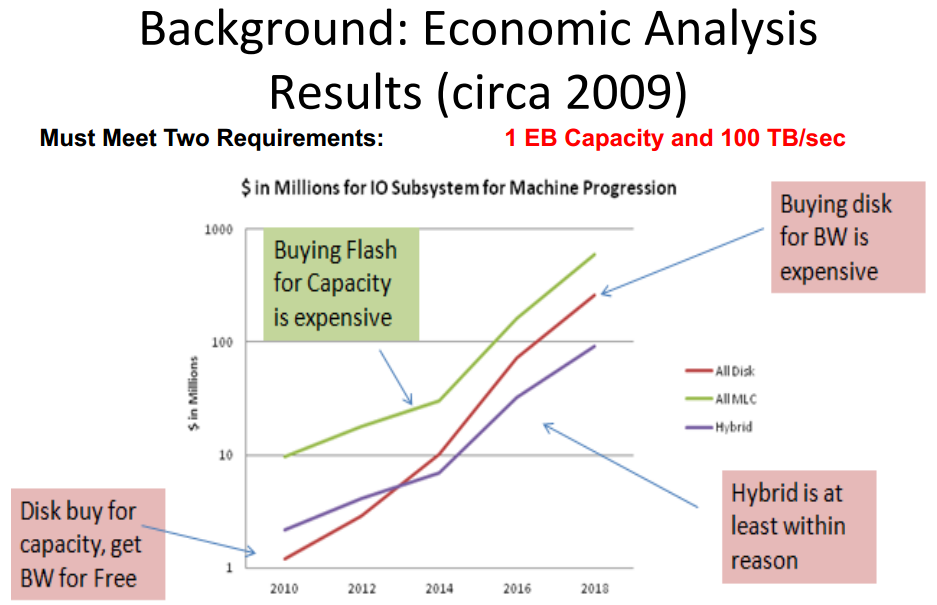
Takeaway: Plotting Million Dollars on a log scale means you have hit the big time. (image courtesy HPC User Forum)
Gary pointed out that, “this was the first time he had to plot millions of dollars for storage using a log scale“.
Economic drivers
The economics are driving the development of “Burst Buffers” to fill the bandwidth gap being created by large numbers of large memory computational nodes. Basically, you need a very fast checkpoint/restart to keep that expensive leadership class system computing rather than waiting on I/O.

Gap in current storage paradigm needed for leadership class checkpoint/restart. (image courtesy HPC user forums)

Economics driving the need for burst buffers (image courtesy HPC user forums)
Archive economics (tape is dead)
Gary notes, “Capacity is no longer the sole cost driver for Archive as it has been in the last 25 years. Bandwidth is now contributing in a major way to TCO of Archives”

Forecast archive capacity growth (courtesy HPC user forums)
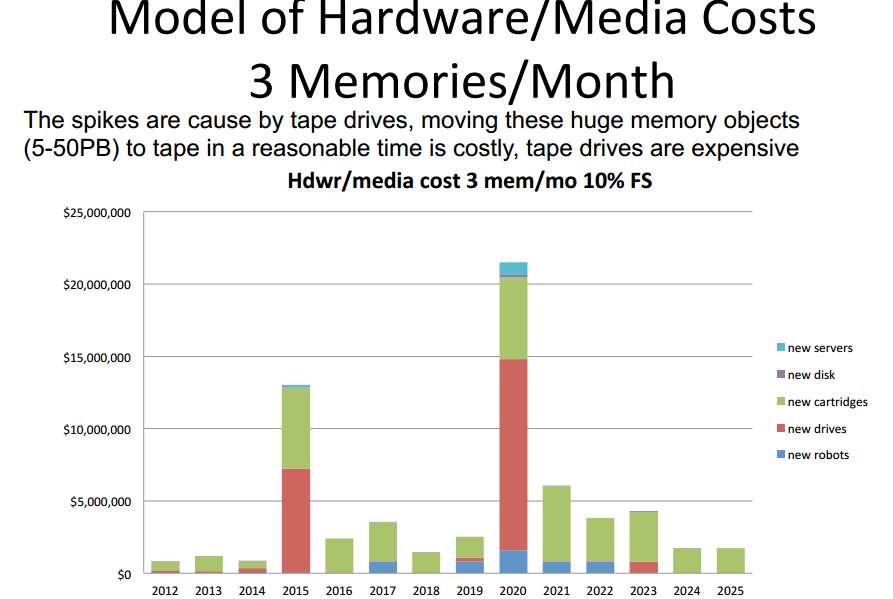
Forecast of cost for three media types (HPC user forum)
What do we do about this Archive Problem?
- All disk Pre-Archive (Campaign Storage)
- Contemplate 100k-1 Million disks
- Power management, with spin up 10,000 drives for parallel transfer
- Vibration management if you want to use inexpensive drives running 10,000 in parallel
- Mean Time To Data Loss needs to rival tape at a reasonable cost and disk array rebuild is probably not tolerable. (No RAID!)
- Similar to ShutterFly/DropBox in usage patterns but we have to eat Petabyte single images, their max image size is a 5 orders of magnitude smaller
- Direction may be to leverage cloud server side provider technologies like:
- Erasure
- Power management
- Object Store mechanisms
Solution: Dare to let the storage system fail
Scary but a reasonable argument based on the economics at this scale.
Gary puts forth a new storage abstraction:
- Support POSIX for quite a while – but exploitation requires changes
- Objects instead of files
- Array objects , Blobs, and Key-values
- Containers instead of directories
- Snapshots for efficient COW across sets of objects (with provenance)
- Transactions for atomic operations across sets of objects
- List IO and Async
- Explicit Burst Buffer management exposed to app or system
- Migrate, purge, pre-stage, mul0-format replicas, semantic resharding
- End-to-end data integrity
- Checksums stored with data, app can detect silent data corruption
- Co-processing analysis on in-transit data
- Query and reorganize the placement of data structures before analysis and shipping
- Work flow will need to take into consideration expense of going to disk and especially to archive
Utilize data access objects (DAOS) where portions of the objects (shards) are distributed across file systems. Further, augment the POSIX semantic to support this model. HDF5 is a current working model.

Fast Forward I/O Architecture (image courtesy HPC user forums)
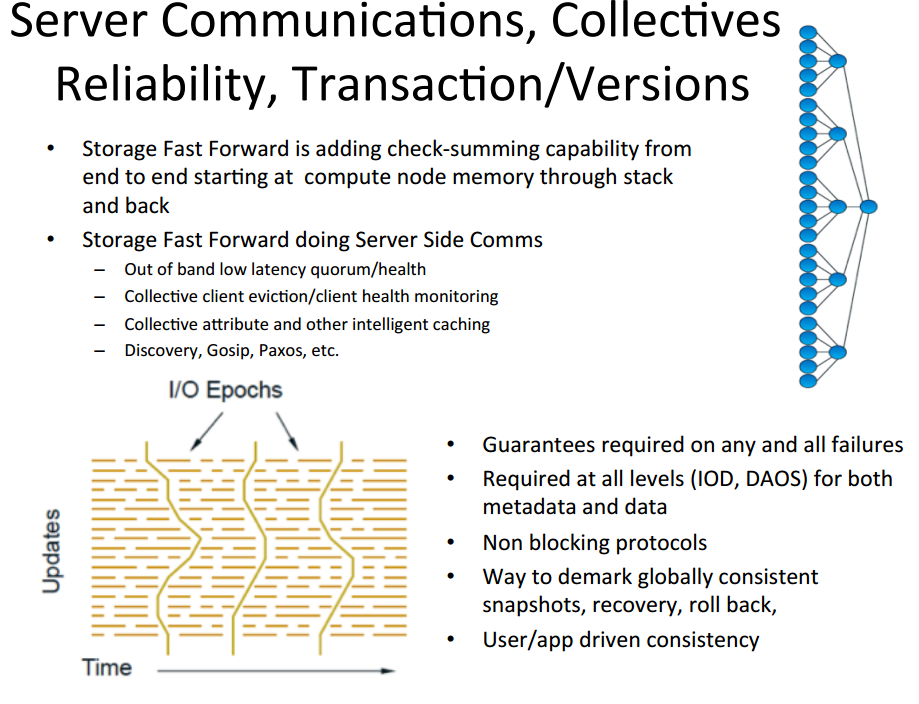
Server communications and reliability (image courtesy HPC user forums)

Distributed arrays of objects (image courtesy HPC user forums)
Leave a Reply