
Scheduled for delivery in mid-2016, NERSC's next-generation supercomputer, a Cray XC, will be named after Gerty Cori, the first American woman to be honored with a Nobel Prize in science. The Cory supercomputer will use Intel’s next-generation Intel® Xeon Phi™ processor –- code-named “Knights Landing” -- a self-hosted, manycore processor with on-package high bandwidth memory … [Read more...]
ExaFMM: An Exascale-capable, TF/s per GPU or Xeon Phi, Long-Range Force Library for Particle Simulations

Rio Yokota has implemented exaFMM, a Fast Multipole Method library to speed applications that must quickly calculate the effects of long-range forces such as gravity or magnetism on discrete particles in a simulation. Based on work he performed as a post-doc with Lorena Barba, the open-source FMM library runs on GPUs, multicore, and Intel Xeon Phi plus most of the … [Read more...]
Run CUDA without Recompilation on x86, AMD GPUs, and Intel Xeon Phi with gpuOcelot
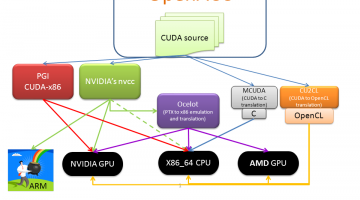
Various pathways exist to run CUDA on a variety of different architectures. The freely available gpuOcelot project is unique in that it currently allows CUDA binaries to run on NVIDIA GPUs, AMD GPUs, x86 and Intel Xeon Phi at full speed without recompilation. It works by dynamically analyzing and recompiling the PTX instructions of the CUDA kernels so they can run on the … [Read more...]
Micron’s New Automata Processor

Adding computation to memory is a fantastic way to accelerate applications and real-time solutions. Content addressable memory (CAM) is a widespread and compelling example of how hardware can speed table lookups. (Most virtual memory computers utilize CAM to perform page lookups.) Micron recently announced the Automata Processor (AP) that implements an NFA (Non-deterministic … [Read more...]
OpenCL 2.0 Conformance Test Suite

The adage with OpenCL is "write once - test everywhere" is being addressed by the Khronos organization through the release of the OpenCL 2.0 test suite. The Khronos™ Group today announced the availability of the official conformance test suite for the OpenCL 2.0 specification, making it possible for implementers to certify that their implementations are officially conformant … [Read more...]
TACC Intel Xeon Phi Training April 22 2014

Where: Texas Advanced Computing Center, J.J. Pickle Research Campus, ROC Building 196, 10100 Burnet Road Austin, TX 78758 When: Tuesday, April 22, 2014, 8:30 AM - 4:00 PM This one-day training will provide software developers the foundation needed for modernizing their code to take advantage of parallel architectures found in both the Intel® Xeon® processor and the Intel® … [Read more...]
TechEnablement Adds Study Guides for CUDA, OpenACC, OpenCL, and Intel Xeon Phi
Today techEnablement.com has provided study guides to help students "learn to change the world" with supercomputing for the masses . The study guides cover: CUDA OpenACC OpenCL Intel Xeon Phi … [Read more...]
Intel Xeon Phi for CUDA Programmers
Both GPU and Xeon Phi coprocessors provide high degrees of parallelism that can deliver excellent application performance. For the most part, CUDA programmers with existing application code have already written their software so it can run well on Phi coprocessors. The key to performance lies in understanding the differences between these two architectures. Author's note: To … [Read more...]
Intel Releases OpenCL™ 1.2 Support for Xeon Phi™ Coprocessors

The Intel press room announced that OpenCL support is now available (link). The new SDK broadens options for developers on Intel® architecture and includes tools, optimization guides and training. The SDK helps OpenCL developers improve performance and efficiency on Intel® Xeon Phi™ coprocessors and Intel® Xeon® processors For those interested in using OpenCL to program … [Read more...]
HPC Balance and Common Sense
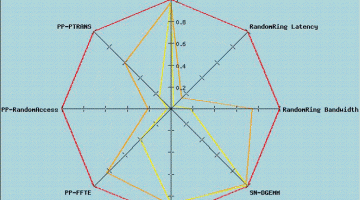
Key concepts for any procurement, system design, or system analysis are presented in my 2007 Scientific Computing article ( link ). A common sense approach is to keep what works and improve on what doesn’t. In other words, measure the performance characteristics of your current system(s) and keep those characteristics that support your workloads and improve on any that might … [Read more...]