
Following Jen-Hsun's strategy to enable those who wish to use NVIDIA chips, developers can win a Jetson K1, get free access to the latest Tegra GPUs. Also those with big computations can submit INCITE proposals to run on the ORNL Titan supercomputer. Ends today (4/30/14) to possibly win a Jetson K1 (link) merely by submitting an idea via … [Read more...]
Run CUDA without Recompilation on x86, AMD GPUs, and Intel Xeon Phi with gpuOcelot
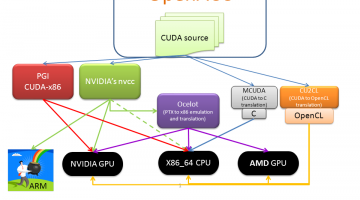
Various pathways exist to run CUDA on a variety of different architectures. The freely available gpuOcelot project is unique in that it currently allows CUDA binaries to run on NVIDIA GPUs, AMD GPUs, x86 and Intel Xeon Phi at full speed without recompilation. It works by dynamically analyzing and recompiling the PTX instructions of the CUDA kernels so they can run on the … [Read more...]
K1-powered NVIDIA Shield 2 Benchmarks Appear

The good folks at Tom's Hardware are lending credibility to the Antutu benchmarks of a K1 powered NVIDIA Shield 2 (link). It is not surprising that the NVIDIA Shield would be one of the first platforms to contain the newest NVIDIA Tegra chip. The claimed specs for the Shield-2 appear reasonable: A screen resolution of 1440 x 810, 4 GB of RAM 16 GB of internal … [Read more...]
(4/24 update) Signals from Nvidia’s Sumit Gupta

Sumit Gupta is a busy man. Named by HPCwire as a 2013 "Person to Watch", Sumit does not idly take time to create a blog post unless it conveys a message about the NVIDIA Tesla development and marketing effort. His recent blog, "Fostering an Explosion of Innovation in the Data Center", posted by Steve Hamm, recognizes how the data-center is going to be supporting mobile … [Read more...]
Inside NVIDIA’s Unified Memory: Multi-GPU Limitations and the Need for a cudaMadvise API Call

The CUDA 6.0 Unified Memory offers a “single-pointer-to-data” model that is similar to CUDA’s zero-copy mapped memory. Both make it trivially easy for the programmer to access memory on the CPU or GPU, but applications that use mapped memory have to perform a PCI bus transfer occur every time a memory access steps outside of a cache line while a kernel running in a Unified … [Read more...]
Battery Powered Supercomputing for the Masses: First Impression of the NVIDIA Jetson TK1 board

GTC 2014 demonstrated that we have now entered the "Battery Powered Supercomputing for the Masses" era. I had the opportunity to experience a Jetson TK1 board running ubuntu 13.04 at the hands-on lab. First impressions were very positive with a snappy response to the Ubuntu window system.. The GTC hands-on labs are oriented for techies and not the press. They provide a very … [Read more...]
Deep-learning Teaching Code Achieves 13 PF/s on the ORNL Titan Supercomputer
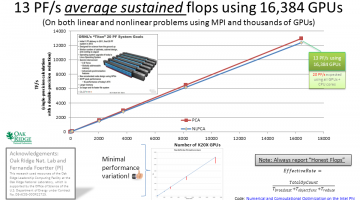
The deep-learning teaching code described in my book, "CUDA Application Design and Development" [Chapters 2, 3, and 9] plus online tutorials achieved 13 PF/s average sustained performance using 16,384 GPUs on the Oakridge Titan supercomputer. Full source code for my teaching code can be found on github in the farbopt directory. Nicole Hemsoth at HPCwire noted these CUDA … [Read more...]
TechEnablement Adds Study Guides for CUDA, OpenACC, OpenCL, and Intel Xeon Phi
Today techEnablement.com has provided study guides to help students "learn to change the world" with supercomputing for the masses . The study guides cover: CUDA OpenACC OpenCL Intel Xeon Phi … [Read more...]
Intel Xeon Phi for CUDA Programmers
Both GPU and Xeon Phi coprocessors provide high degrees of parallelism that can deliver excellent application performance. For the most part, CUDA programmers with existing application code have already written their software so it can run well on Phi coprocessors. The key to performance lies in understanding the differences between these two architectures. Author's note: To … [Read more...]
CUDA 6.0 Released

The CUDA 6 Production Release is now available for download at www.nvidia.com/getcuda. This version of the toolkit includes features that further simplify parallel programming like: • Unified Memory: simplifies programming by enabling applications to access the CPU and GPU memory without the need to manually copy data. • Drop-in Libraries: automatically accelerate … [Read more...]