The deep-learning teaching code described in my book, “CUDA Application Design and Development” [Chapters 2, 3, and 9] plus online tutorials achieved 13 PF/s average sustained performance using 16,384 GPUs on the Oakridge Titan supercomputer. Full source code for my teaching code can be found on github in the farbopt directory.
Nicole Hemsoth at HPCwire noted these CUDA based results and potential to achieve 20 PF/s using OpenACC:
On the code front, OpenACC was a hot topic among the HPC set. Rob Farber did an excellent job of highlighting some of the key trends in programming and optimizing for GPUs at large scale. He presented on new results that extend machine learning and big data analysis to 13 petaflops average sustained performance across 16,384 GPUs on Titan—a very popular topic.
As you can see in the slide below from my GTC 2014 presentation “S4178 Killer-app Fundamentals: Massively-parallel data structures, Performance to 13 PF/s, Portability, Transparency, and more” the near-linear scaling utilizing MPI looks linear – meaning that we achieve close to a 16,000-times speedup when using 16k GPUs.

My online tutorials showed it is possible to get close to a TF/s average sustained performance on a single device for problems (labeled PCA below) and excellent 600 – 800 GF/s performance a nonlinear machine-learning problem (labeled NLPCA below).

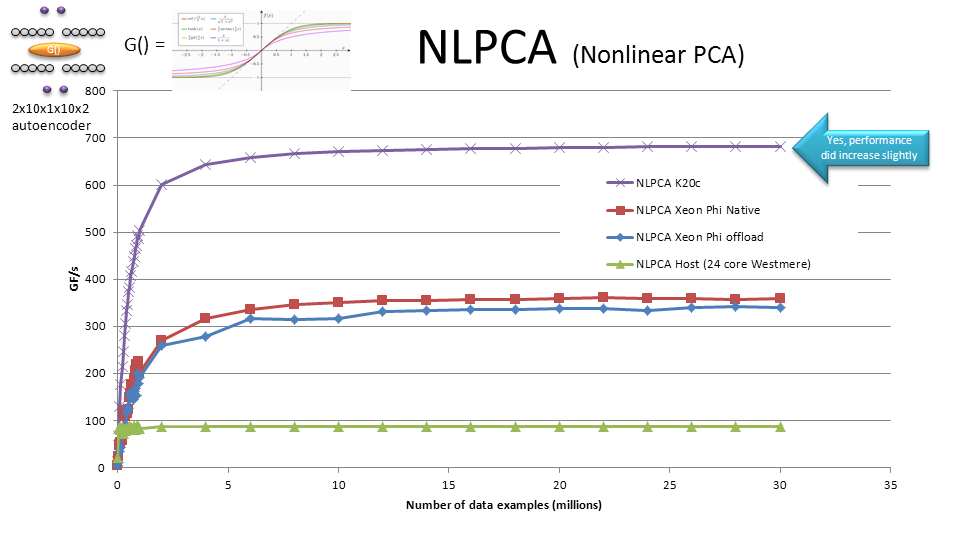
Update: The CUDA-6.5 release boosted this performance by 100s of GF/s. We look forward to re-running on the ORNL Titan.

CUDA-6.5 significantly boost performance on a non-linear NLPCA, machine-learning, and deep-learning codes

CUDA-6.5 significantly boost performance on PCA, machine-learning, and deep-learning codes
As the insert in the previous slide shows, performance variation (shown by the red lines) across the 16k nodes is minimal so the average sustained performance (an important measure) remains high.

Basically, the linear scaling performance means that leadership class supercomputers like Titan can deliver substantial, near-peak performance. My tutorial, “Numerical and Computational Optimization on the Intel Phi” shows how to achieve 2.2 PF/s average sustained performance on the TACC Stampede supercomputer using MPI and 3,000 Intel Xeon Phi coprocessors. Full source code is provided in the tutorial. The ORNL run utilized a slightly modified version of the code in my Intel Xeon Phi tutorial.
The near-linear runtime is achieved through the SIMD mapping I created in the 1980s.

Farber High-Performance and Scalable Deep-learning mapping
The farbopt teaching code utilizes the freely available nlopt optimization package nlopt numerical optimization package as the “Optimization Method” indicated in the previous picture.
![]()
This teaching code can also be used to program deep-learning systems to perform a task.
The use of MPI is mandatory as each Titan K20x GPU is programmed using one GPU per MPI process as shown below

Additional system information can be found in the Cray XK7 brochure.
More information about programming the ORNL titan supercomputer can be found in the accelerator user guide.
Click here for more TechEnablement machine-learning articles and tutorials!
Leave a Reply