
Rio Yokota has implemented exaFMM, a Fast Multipole Method library to speed applications that must quickly calculate the effects of long-range forces such as gravity or magnetism on discrete particles in a simulation. Based on work he performed as a post-doc with Lorena Barba, the open-source FMM library runs on GPUs, multicore, and Intel Xeon Phi plus most of the … [Read more...]
Inside NVIDIA’s Unified Memory: Multi-GPU Limitations and the Need for a cudaMadvise API Call

The CUDA 6.0 Unified Memory offers a “single-pointer-to-data” model that is similar to CUDA’s zero-copy mapped memory. Both make it trivially easy for the programmer to access memory on the CPU or GPU, but applications that use mapped memory have to perform a PCI bus transfer occur every time a memory access steps outside of a cache line while a kernel running in a Unified … [Read more...]
Deep-learning Teaching Code Achieves 13 PF/s on the ORNL Titan Supercomputer
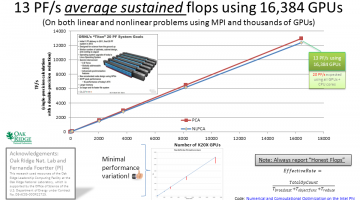
The deep-learning teaching code described in my book, "CUDA Application Design and Development" [Chapters 2, 3, and 9] plus online tutorials achieved 13 PF/s average sustained performance using 16,384 GPUs on the Oakridge Titan supercomputer. Full source code for my teaching code can be found on github in the farbopt directory. Nicole Hemsoth at HPCwire noted these CUDA … [Read more...]
Farber teaches massively parallel computing to grade 6 – 12 students in Saudi Arabia

My book, “CUDA Application Design and Development” [English][Chinese] and Doctor Dobbs tutorials coupled with the rapid adoption of GPU computing have given me the opportunity to speak and teach around the world. This January, I had the pleasure of traveling to Jeddah, Saudi Arabia to speak and teach a short course on OpenACC and CUDA at KAUST (the King Abdullah University of … [Read more...]