This chapters documents the implementation of a parallel distributed memory out-of-core (OOC) solver for performing LU and Cholesky factorizations of a large dense matrix on clusters equipped with Intel Xeon Phi coprocessors.

The code was ported from CUDA with high-level library routines in CUBLAS
- This matches well with the offload model for the coprocessor using the Intel Language Extensions for Offload (Intel LEO) #pragma compiler directives
- “The translation of CUBLAS calls to using equivalent operations in MKL is quite straight-forward.”
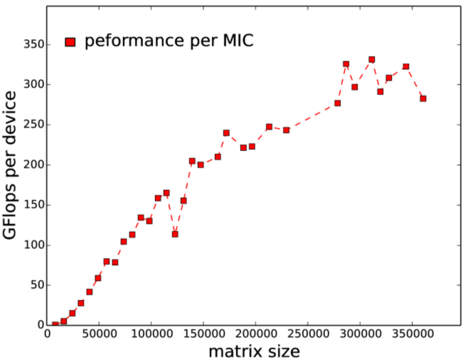
Image courtesy Morgan Kaufmann
Out of core performance results are expressed via the memory ratio, ρ, between the host and device.
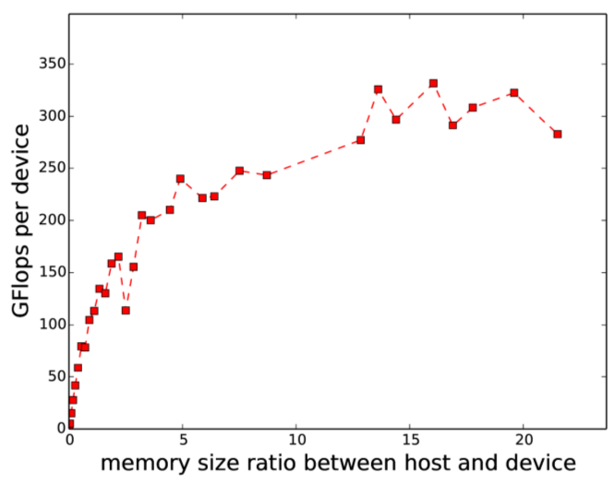
Image courtesy Morgan Kaufmann
Strong scaling study on Beacon

The processor grid is 2 ρ ∗ ρ where ρ 2 nodes are used and ρ is up to 6. (Image courtesy Morgan Kaufmann)
Chapter Authors

Eduardo D’Azevedo
Eduardo D’Azevedo is a staff scientist in the Computational Mathematics Group at the Oak Ridge National Laboratory. He obtained his B. Math in 1983, M. Math in 1985, and PhD. in 1989 all from the Department of Com- puter Science in the Faculty of Mathematics at the University of Waterloo, Ontario, Canada. D’Azevedo’s current research interests include develop- ing highly scalable parallel solvers that can take advantage of acceleration on Graphics Processor Unit and in enhancing the parallel efficiency of scien- tific applications running on leadership supercomputers. D’Azevedo has con- tributed to several projects in materials science and fusion in the Scientific Discovery through Advanced Computing (SciDAC) program. He has devel- oped the on out-of-core and compact storage extensions for the ScaLAPACK library and has made fundamental contributions in optimal mesh generation.

Ki Sing Chan
Ki Sing Chan is an undergraduate student at the Chinese University of Hong Kong majoring in Mathematics and Information Engineering with a minor in Computer Science. He is expected to graduate in 2015. His first research experience took place in the Oak Ridge National Laboratory in Tennessee during the summer break in 2013. The research focuses on the implementation of a Cholesky Factorization algorithm for large dense matrix. He continued the research work part-time after he went back to Hong Kong. He is working at Stanford University for a DNA sequencing research project in summer 2014. He is interested in becoming a software engineer while getting more interested with the idea of a research career.

Shi-Quan Su
As a HPC Consultant, Shiquan works closely with the users of NICS from various disciplines. The offered supports include various levels, such as software installation, performance improvement. He has the specialty to help the users to migrate the codes to the novel platforms available at NICS, such as the Multiple General Purpose Graphical Processing Units (GPGPUs) Cluster. Before he joined NICS, Shiquan was a Post Doctoral Research Associate at Oak Ridge National Lab and Louisiana State University. He worked on state-of-art large scale Quantum Monte Carlo simulation for the high transition temperature superconductive materials. Shiquan obtained his Bsc in Physics from Nanjing University in 2002, Mphil in Physics from Peking University in 2005, and PhD in Physics from the Chinese University of Hong Kong in 2008.

Kwai Wong
Dr. Kwai Wong is the deputy director of the Campus Programs group at JICS. He is the director of the CFD Laboratory in the Mechanical, Aerospace, and Biomedical Engineering at the University of Tennessee, Knoxville. Kwai’s background includes numerical linear algebra, parallel computing, computa- tional fluid dynamics, and finite element method. Dr. Wong holds a BS in aerospace engineering, a MS in Math and a PhD in Engineering Science from The University of Tennessee.
Click to see the overview article “Teaching The World About Intel Xeon Phi” that contains a list of TechEnablement links about why each chapter is considered a “Parallelism Pearl” plus information about James Reinders and Jim Jeffers, the editors of High Performance Parallelism Pearls.
Leave a Reply