
Sparsh Mittal and Jeff Vetter provide a survey of the comparative energy efficiency of GPUs relative to FPGAs and CPUs in their Jan. 2015 ACM Computing Surveys (CSUR) paper, "A Survey of Methods for Analyzing and Improving GPU Energy Efficiency" in which they observe a general energy efficiency hierarchy where, "it is clear that although for majority of works, FPGAs are … [Read more...]
Plan Ahead – SC15 Housing Site Open For Room Reservations!

The SC15 housing site is now open through October. The conference takes place Nov 15-20 in Austin, Texas. IMPORTANT DATES AND DEADLINES March 2, 2015 – Hotel reservation system opens September 20, 2015 – Last day for submitting occupancy lists for exhibitor room blocks October 16, 2015 – Last day for making hotel reservations October 16, 2015 – Last day for canceling … [Read more...]
NP-Complete Parallel Thread Placement Addressed in Milliseconds via MIT “Best Paper” Heuristic

The problem of jointly allocating computations and data is a known NP-hard problem. A heuristic proposed by MIT researchers Nathan Beckmann, Po-An Tsai, and Daniel Sanchez recently the best-paper award at the IEEE Symposium on High-Performance Computer Architecture for a place-and-route algorithm that runs in milliseconds and finds a solution that is more than 99 percent as … [Read more...]
Horst Simon Explains the HPC Slowdown (and Human Brain Scale Simulation)
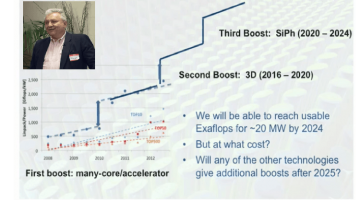
HPC luminary Horst Simon, the Berkeley Lab Deputy Director, gave a marvelous talk at an HPC meetup event in San Francisco on Feb 10 covering power efficiency and the movement towards exascale computing. Horst presented data and the conclusion that the June 2008 - June 2013 five-year span marks a turning point where the growth attributed to Moore’s law and parallelism are … [Read more...]
Power Profiling Shows Simple Changes To Save Megawatts of Power On Leadership Supercomputers

A challenge with profiling applications lies in how to interpret the profile results. In particular, most programmers do not give the power profile plots more than a cursory glance. Following is an example waterfall plot showing the power utilization for an NWChem run on Intel Xeon Phi coprocessors: My recent column in Scientific Computing, "Using Profile Information for … [Read more...]
2015 HPC Advisory Council Presentations Available Online

The presentation slides from the 2015 HPC Advisory Council held at Stanford are now available for all to view on the Internet. InsideHPC is bringing videos of the presentations online as well. http://youtu.be/nhF9Wc9_RQY … [Read more...]
MAGMA LU Decompositions, Factorizations, and Eigensolvers for Intel Xeon Phi Coprocessors Released

MAGMA MIC 1.3.1 now provides implementations for MAGMA's one-sided (LU, QR, and Cholesky) and two-sided (Hessenberg, bi- and tridiagonal reductions) dense matrix factorizations, as well as linear and eigenproblem solver for Intel Xeon Phi Coprocessors. The MAGMA MIC 1.3.1 release adds Added orthogonal transformations … [Read more...]
Fine-Tuning Vectorization and Memory Traffic on Intel Xeon Phi Coprocessors

Andrey Vladimirov at ColFax International has posted source code and a paper, "Fine-Tuning Vectorization and Memory Traffic on Intel Xeon Phi Coprocessors: LU Decomposition of Small Matrices" on the ColFax site. Andrey notes, "Benchmarks show that the discussed optimizations improve the application performance on the coprocessor by a factor of 2.8 compared to the unoptimized … [Read more...]
CUDA 7 For Registered Developers – LAPACK Dense Solvers 3-6x faster than MKL

The CUDA Toolkit 7.0 Release Candidate (RC) is now available to members of NVIDIA’s free registered developer program. Especially interesting is the claim of 3-6x faster LAPACK dense solvers over MKL (The Intel Math Kernel Library). C++11 support makes it easier for C++ developers to accelerate their applications Write less code with ‘auto’ and ‘lambda’, especially when … [Read more...]
ORNL Introductory Tutorials On Concurrent Kernels

The OLCF at Oakridge National Laboratory (ORNL) is working to educate users about how to best use their computing resources. As part of that process, the OLCF has published two very introductory tutorials to teach how to utilize concurrent kernels on their systems. Part 1 (concurrent kernels) and Part 2 (batched library calls) teach how to launch concurrent kernels using CUDA … [Read more...]