
Following is the full, unabridged text of the chapter 1 introduction (written by James Reinders) to High Performance Parallelism Pearls. Thanks to Morgan Kaufmann, James Reinders, and Jim Jeffers for giving permission so TechEnablment can make this available. After reading what James wrote, you will see that summarizing the introduction would simply have left out too much … [Read more...]
Teaching The World About Intel Xeon Phi

The newest book by James Reinders and Jim Jeffers, “High Performance Parallelism Pearls” distills the experience of sixty-nine HPC experts into twenty-eight chapters designed to teach the world about the performance capabilities of the massively-parallel Intel® Xeon Phi™ family of products. Source code for numerous working examples selected for their educational content, … [Read more...]
Deep-learning Teaching Code Achieves 13 PF/s on the ORNL Titan Supercomputer
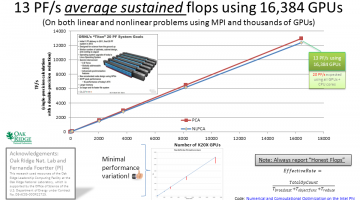
The deep-learning teaching code described in my book, "CUDA Application Design and Development" [Chapters 2, 3, and 9] plus online tutorials achieved 13 PF/s average sustained performance using 16,384 GPUs on the Oakridge Titan supercomputer. Full source code for my teaching code can be found on github in the farbopt directory. Nicole Hemsoth at HPCwire noted these CUDA … [Read more...]