
Microway is hosting a webinar, "The Faster Path to Discovery: New Details on the Intel® Xeon Phi™ Product Family" that will cover the next-generation Knights Landing processor on June 24. Register here to attend. … [Read more...]
TACC Intel Xeon Phi – MIC – User Group Meeting July 8-9

TACC is hosting a meeting of the Intel Xeon Phi user group (IXPug) in Austin, TX July 8-9, 2014. IXPug has been created to promote the exchange of user experiences in adopting and using the Phi processors. Registration is free and open until July 1, 2014. Attend IXPug to start or enhance your Xeon (X86) programming skills on the Intel Many Integrated Core (MIC) architecture, … [Read more...]
WebCL for Safari

Cross-platform interest in WebCL is expanding with support for Firefox, Chrome as well as Safari. WebCL provides a tremendous opportunity to exploit parallelism on client-side machines. Thanks for to Antonio Gomes (Twitter @tonikitoo) who brought the Safari webkit-webcl implementation to our attention! The SMAST Computational Laboratory (CMLab) at the School for Marine … [Read more...]
The Missing Link in NVlink, or “Hello Pascal” bye-bye PCI bus limitations!
Say hello to NVlink, a new technology by NVIDIA that is not constrained by PCIe bandwidth and latency limitations, but you will have to wait for the Pascal generation of 2016 GPUs to get it. NVlink is NVIDIA's properitary "DRAM speed and latency" class interface for CPU to GPU and GPU to GPU point-to-point communications. The basic building block for NVLink is a high-speed, … [Read more...]
OpenCL Haswell Iris 5200 Performance Results – 800 GF/s Peak Performance
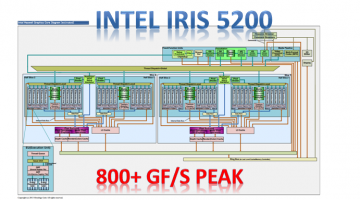
The Intel Haswell chip contains an integrated GPU that delivers significantly better OpenCL performance than an NVIDIA GeForce GT 650M - exceeding 800 GF/s peak performance. Allan MacKinnon at PixelIO has been investigating the OpenCL performance of this device and has been finding a plethora of on-gpu registers but also that the GPU appears to be both power and thermally … [Read more...]
PGI 14.4 is now released with lots of OpenACC C++ Goodness!

PGI 14.4 is now released with lots of OpenACC C++ goodness. Give it a try! Here is the link for or those with existing licenses. If need be, get a 15 day trial license and use some of my OpenACC tutorials. PGI Trial keys Trial license keys are used for evaluating PGI software. They are valid for fifteen days. If you haven't already done so, you … [Read more...]
OpenCL + Java Acceleration on Mobile Promises 8x speedup with 3x Less Power

In what will certainly become a flood of papers about GPU acceleration of Java applications on mobile devices, a masters theses by Iype P. Joseph at the University of Ottawa claims 8x performance gains and 3x reductions in power consumption through the use of Java binding with OpenCL 1.1 on a a Freescale i.MX6Q SabreLite board. With NVIDIA entering the programmable mobile GPU … [Read more...]
ExaFMM: An Exascale-capable, TF/s per GPU or Xeon Phi, Long-Range Force Library for Particle Simulations

Rio Yokota has implemented exaFMM, a Fast Multipole Method library to speed applications that must quickly calculate the effects of long-range forces such as gravity or magnetism on discrete particles in a simulation. Based on work he performed as a post-doc with Lorena Barba, the open-source FMM library runs on GPUs, multicore, and Intel Xeon Phi plus most of the … [Read more...]
Run CUDA without Recompilation on x86, AMD GPUs, and Intel Xeon Phi with gpuOcelot
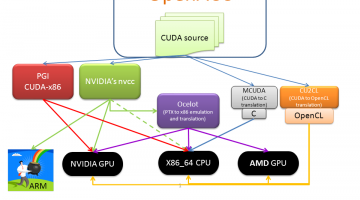
Various pathways exist to run CUDA on a variety of different architectures. The freely available gpuOcelot project is unique in that it currently allows CUDA binaries to run on NVIDIA GPUs, AMD GPUs, x86 and Intel Xeon Phi at full speed without recompilation. It works by dynamically analyzing and recompiling the PTX instructions of the CUDA kernels so they can run on the … [Read more...]
K1-powered NVIDIA Shield 2 Benchmarks Appear

The good folks at Tom's Hardware are lending credibility to the Antutu benchmarks of a K1 powered NVIDIA Shield 2 (link). It is not surprising that the NVIDIA Shield would be one of the first platforms to contain the newest NVIDIA Tegra chip. The claimed specs for the Shield-2 appear reasonable: A screen resolution of 1440 x 810, 4 GB of RAM 16 GB of internal … [Read more...]