
PGI released their 14.4 and upcoming 14.7 OpenACC 2.0 roadmap. The expectation is that we will see the 14.4 release in early May and the 14.7 release in early July. Note: these are not official PGI dates. Analysis: The 14.4 support of atomic operations will enable many low-wait algorithms such as counters and massively parallel stacks. Improved reduction performance in … [Read more...]
(4/24 update) Signals from Nvidia’s Sumit Gupta

Sumit Gupta is a busy man. Named by HPCwire as a 2013 "Person to Watch", Sumit does not idly take time to create a blog post unless it conveys a message about the NVIDIA Tesla development and marketing effort. His recent blog, "Fostering an Explosion of Innovation in the Data Center", posted by Steve Hamm, recognizes how the data-center is going to be supporting mobile … [Read more...]
Inside NVIDIA’s Unified Memory: Multi-GPU Limitations and the Need for a cudaMadvise API Call

The CUDA 6.0 Unified Memory offers a “single-pointer-to-data” model that is similar to CUDA’s zero-copy mapped memory. Both make it trivially easy for the programmer to access memory on the CPU or GPU, but applications that use mapped memory have to perform a PCI bus transfer occur every time a memory access steps outside of a cache line while a kernel running in a Unified … [Read more...]
TechEnablement Adds Study Guides for CUDA, OpenACC, OpenCL, and Intel Xeon Phi
Today techEnablement.com has provided study guides to help students "learn to change the world" with supercomputing for the masses . The study guides cover: CUDA OpenACC OpenCL Intel Xeon Phi … [Read more...]
Intel Xeon Phi for CUDA Programmers
Both GPU and Xeon Phi coprocessors provide high degrees of parallelism that can deliver excellent application performance. For the most part, CUDA programmers with existing application code have already written their software so it can run well on Phi coprocessors. The key to performance lies in understanding the differences between these two architectures. Author's note: To … [Read more...]
Intel Releases OpenCL™ 1.2 Support for Xeon Phi™ Coprocessors

The Intel press room announced that OpenCL support is now available (link). The new SDK broadens options for developers on Intel® architecture and includes tools, optimization guides and training. The SDK helps OpenCL developers improve performance and efficiency on Intel® Xeon Phi™ coprocessors and Intel® Xeon® processors For those interested in using OpenCL to program … [Read more...]
HPC Balance and Common Sense
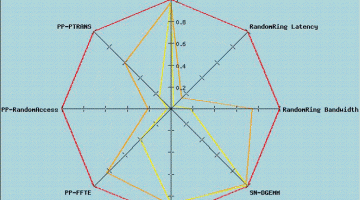
Key concepts for any procurement, system design, or system analysis are presented in my 2007 Scientific Computing article ( link ). A common sense approach is to keep what works and improve on what doesn’t. In other words, measure the performance characteristics of your current system(s) and keep those characteristics that support your workloads and improve on any that might … [Read more...]
Pragmatic Parallelism Part 1: Introducing OpenACC 1.0
OpenACC lets you program in parallel C/C++ and Fortran in a manner that is concise and where the same source code can be recompiled to run on AMD GPUs, NVIDIA GPUs, Intel Xeon Phi, x86, and ARM. View at Dr. Dobbs (http://www.drdobbs.com/parallel/easy-gpu-parallelism-with-openacc/240001776) This is the first in a series of articles by Rob Farber on OpenACC directives, … [Read more...]
Farber teaches massively parallel computing to grade 6 – 12 students in Saudi Arabia

My book, “CUDA Application Design and Development” [English][Chinese] and Doctor Dobbs tutorials coupled with the rapid adoption of GPU computing have given me the opportunity to speak and teach around the world. This January, I had the pleasure of traveling to Jeddah, Saudi Arabia to speak and teach a short course on OpenACC and CUDA at KAUST (the King Abdullah University of … [Read more...]