
Professor Paul Shellard, the COSMOS Director at Cambridge University reports a 30x speedup of the heavily utilized production WALLS code and he notes "Our expectation is that all our cosmological field theory codes, like WALLS, will have similarly large speed-ups when optimized and ported to Xeon Phi." Currently the project is transferring a larger portion of the CMB analysis … [Read more...]
Parallel Evaluation Of Fault Tree Expressions

Readers are guided through a progression from a scalar fault tree code to one mapped effectively to Intel Xeon Phi with the open-source ispc (Intel SPMD Program Compiler). Fault trees express failure relationships between systems using Boolean logic to evaluate the vulnerability of systems based on component reliability, system redundancy, physical protection, and other — … [Read more...]
Micron Automata Processor SDK Now Available – Includes Online Demo!
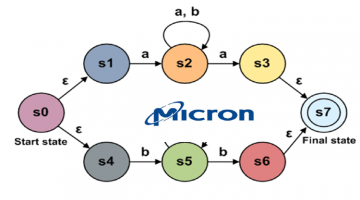
Click here to try a web-enabled intro simulation or visit micronautomata.com to sign up for a full preview of the Micron Automata Processor SDK (Software Development Kit) that includes a visual development environment, compiler, design rules checker, regular expression to automata generator and AP simulator. The SDK is also available through membership with the Center for … [Read more...]
Optimizing for Reacting Navier‐Stokes Equations

Antonio Valles and Weiqun Zhang note the optimizations discussed in their High Performance Parallelism Pearls chapter that, "significantly improved concurrency on both Intel Xeon Phi coprocessors and Intel Xeon processors" by transforming a fine-grain thread parallel approach to a more coarse-grain, memory allocation considerate approach plus improving vectorization. They … [Read more...]
Microsoft Roomalive Creates Augmented Reality Room At Home
Ditch the AR goggles! In their paper, "RoomAlive: Magical Experiences Enabled by Scalable, Adaptive Projector-Camera Units" Microsoft researchers discuss a proof-of-concept prototype that transforms any room into an immersive, augmented entertainment experience. The basic building blocks are projector-depth camera units that create a unified model of the room with no … [Read more...]
NASA Charts Path For CFD To 2030 – Projects Future Computer Technology!
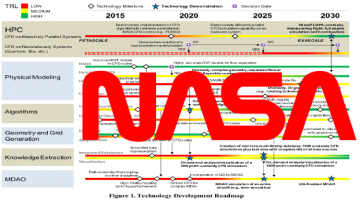
The recent NASA-sponsored report CFD Vision 2030 Study: A Path to Revolutionary Computational Aerosciences is a must-read for everyone involved in Computational Fluid Dynamics and a very interesting read for those involved in computer technology. In a nutshell, “A single engineer/scientist must be able to conceive, create, analyze, and interpret a large ensemble of related … [Read more...]
Better Concurrency and SIMD On The HIROMB‐BOOS‐Model (HBM) 3D Ocean Code

By utilizing the strengths of the Intel Xeon Phi coprocessor, the chapter 3 High Performance Parallelism Pearls authors were able to improve and modernize their code and "achieve great scaling, vectorization, bandwidth utilization and performance/watt". The authors (Jacob Weismann Poulsen, Karthik Raman and Per Berg) note, "The thinking process and techniques used in this … [Read more...]
From ‘Correct’ to ‘Correct & Efficient’: a Hydro2D case study with Godunov’s scheme

Poetically noting that "a rising tide lifts all boats", authors Guillaume Colin de Verdière and Jason D. Sewall demonstrate a 12x increase on Intel Xeon Phi and over 5x increase on Intel Xeon using, "a common set of optimizations [that] benefit both general-purpose Xeon processors and more specialized Xeon Phi accelerators" in chapter 2 of High Performance Parallelism … [Read more...]
DARPA Cyber Fault-tolerant Attack Recovery (CFAR) Due Nov 15, 2014

Full proposal due November 15, 2014, the DARPA program to develop "fault tolerant" networks which quickly detect and recover from cyber attacks. Multiple awards are available for TA-1, which is concerned with binary transformation of executables so that they perform the same function, but no longer exhibit the same susceptibility to cyber attack. In addition single awards are … [Read more...]
The Unabridged Chapter 1 Introduction To High Performance Parallelism Pearls

Following is the full, unabridged text of the chapter 1 introduction (written by James Reinders) to High Performance Parallelism Pearls. Thanks to Morgan Kaufmann, James Reinders, and Jim Jeffers for giving permission so TechEnablment can make this available. After reading what James wrote, you will see that summarizing the introduction would simply have left out too much … [Read more...]