
Antonio Valles and Weiqun Zhang note the optimizations discussed in their High Performance Parallelism Pearls chapter that, "significantly improved concurrency on both Intel Xeon Phi coprocessors and Intel Xeon processors" by transforming a fine-grain thread parallel approach to a more coarse-grain, memory allocation considerate approach plus improving vectorization. They … [Read more...]
Better Concurrency and SIMD On The HIROMB‐BOOS‐Model (HBM) 3D Ocean Code

By utilizing the strengths of the Intel Xeon Phi coprocessor, the chapter 3 High Performance Parallelism Pearls authors were able to improve and modernize their code and "achieve great scaling, vectorization, bandwidth utilization and performance/watt". The authors (Jacob Weismann Poulsen, Karthik Raman and Per Berg) note, "The thinking process and techniques used in this … [Read more...]
From ‘Correct’ to ‘Correct & Efficient’: a Hydro2D case study with Godunov’s scheme

Poetically noting that "a rising tide lifts all boats", authors Guillaume Colin de Verdière and Jason D. Sewall demonstrate a 12x increase on Intel Xeon Phi and over 5x increase on Intel Xeon using, "a common set of optimizations [that] benefit both general-purpose Xeon processors and more specialized Xeon Phi accelerators" in chapter 2 of High Performance Parallelism … [Read more...]
The Unabridged Chapter 1 Introduction To High Performance Parallelism Pearls

Following is the full, unabridged text of the chapter 1 introduction (written by James Reinders) to High Performance Parallelism Pearls. Thanks to Morgan Kaufmann, James Reinders, and Jim Jeffers for giving permission so TechEnablment can make this available. After reading what James wrote, you will see that summarizing the introduction would simply have left out too much … [Read more...]
Teaching The World About Intel Xeon Phi

The newest book by James Reinders and Jim Jeffers, “High Performance Parallelism Pearls” distills the experience of sixty-nine HPC experts into twenty-eight chapters designed to teach the world about the performance capabilities of the massively-parallel Intel® Xeon Phi™ family of products. Source code for numerous working examples selected for their educational content, … [Read more...]
Latest Intel SDE Emulates New ISA Instructions For Knights Landing
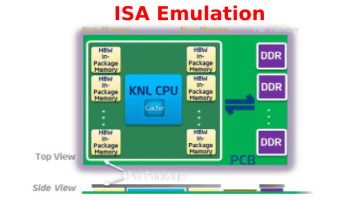
Intel has released a new version of the Intel SDE (Software Development Emulator) so that customers can start working with upcoming instruction set extensions like AVX-512 for Knights Landing. The SDE can be downloaded after accepting a user agreement and used on Windows, Linux, and OS. It can also be used with the GNU gcc. The current version is 7.2 released on July 29, … [Read more...]
GCC 5.0 Provides Full Cilk Plus Support

GNU has announced that GCC 5.0 will provide full support for Cilk Plus. Cilk Plus is an extension to the C and C++ languages to support data and task parallelism on multi-core, vector and Intel Xeon Phi coprocessors.It is reputed to be quite efficient and looks to be easy to use. The Intel icc compiler has supported Cilk Plus for years. GNU support now makes Cilk Plus available … [Read more...]
Dongarra Gives Deep-Learning a Python Interface With RaPyDLI

An NSF-funded project called "Rapid Python Deep Learning Infrastructure", or RaPyDLI received nearly $1 million in NSF grants. The project led by supercomputing luminaries Jack Dongarra (University of Tennessee) and Geoffrey Fox (Indiana University) along with Andrew Ng (Stanford, Baidu and Coursera) will allow users to program deep learning models in Python and port them to … [Read more...]
Lustre Delivers 10x the Bandwidth of NFS on Intel Xeon Phi

Lustre on Intel Xeon Phi delivered 10x the bandwidth of NFS as reported in the 2014 Lustre User Group (LUG) presentation "Running Native Lustre* Client inside Intel® Xeon Phi™ coprocessor" by Dmitry Eremin, Zhiqi Tao and Gabriele Paciucci of Intel Corporation. Network file systems are essential to the current generation of Knights Corner Intel Xeon Phi coprocessors because the … [Read more...]
Shared Memory is Simple on Intel Xeon Phi – supports STL!

Shared memory on Intel Xeon Phi, in OpenCL, and CUDA (via managed memory) greatly simplifies programming by eliminating the need to explicitly define all data transfers between host and device memory. Once these implementations mature, it is likely they will become the standard API that programmers use to access data on both Intel Xeon Phi and GPUs. (They also naturally support … [Read more...]