
Chapter 9 of High Performance Parallelism Pearls presents several optimizations that are usually necessary to obtain good performance on an Intel Xeon Phi coprocessor that include: introducing a softening factor, exploring the impact of single- vs. double-precision, Improving tililing, utilizing an SoA (Structure of Arrays) layout, generating code that does not maintain IEEE … [Read more...]
Optimizing Gather/Scatter Patterns On Intel Xeon Phi

Many modern microarchitectures rely on single-instruction multiple-data (SIMD) execution to provide high compute capabilities in an energy efficient manner. Such microarchitectures including those employed by the most recent Intel Xeon processors and Intel Xeon Phi coprocessors are optimized and/or better suited to dealing with contiguous loads and stores than non-contiguous … [Read more...]
Deep-Learning And Numerical Optimization

The massively parallel mapping and code described in this chapter is generic and can be applied to a broad spectrum of numerical optimization and machine-learning algorithms ranging from neural networks to support vector machines to expectation maximization and independent components analysis. Many of these techniques are heavily used in lucrative data-mining and social media … [Read more...]
Intel Xeon Phi Provides Cambridge 30x Speedup in Production COSMOS WALLS Code

Professor Paul Shellard, the COSMOS Director at Cambridge University reports a 30x speedup of the heavily utilized production WALLS code and he notes "Our expectation is that all our cosmological field theory codes, like WALLS, will have similarly large speed-ups when optimized and ported to Xeon Phi." Currently the project is transferring a larger portion of the CMB analysis … [Read more...]
Parallel Evaluation Of Fault Tree Expressions

Readers are guided through a progression from a scalar fault tree code to one mapped effectively to Intel Xeon Phi with the open-source ispc (Intel SPMD Program Compiler). Fault trees express failure relationships between systems using Boolean logic to evaluate the vulnerability of systems based on component reliability, system redundancy, physical protection, and other — … [Read more...]
Plesiochronous (Loosely Synchronous) Phasing Barriers To Avoid Thread Inefficiencies

Jim Dempsey bests expert Intel programmers by 40% - 50% simply by using a little bit of ingenuity, along with a slightly different programming technique. He notes that, "a substantial portion of previously lost thread barrier wait time" can be recovered simply by using loosely synchronous (plesiochronous) barriers instead of strictly synchronous barriers. Jim points out that, … [Read more...]
Optimizing for Reacting Navier‐Stokes Equations

Antonio Valles and Weiqun Zhang note the optimizations discussed in their High Performance Parallelism Pearls chapter that, "significantly improved concurrency on both Intel Xeon Phi coprocessors and Intel Xeon processors" by transforming a fine-grain thread parallel approach to a more coarse-grain, memory allocation considerate approach plus improving vectorization. They … [Read more...]
NASA Charts Path For CFD To 2030 – Projects Future Computer Technology!
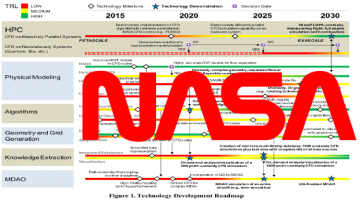
The recent NASA-sponsored report CFD Vision 2030 Study: A Path to Revolutionary Computational Aerosciences is a must-read for everyone involved in Computational Fluid Dynamics and a very interesting read for those involved in computer technology. In a nutshell, “A single engineer/scientist must be able to conceive, create, analyze, and interpret a large ensemble of related … [Read more...]
Better Concurrency and SIMD On The HIROMB‐BOOS‐Model (HBM) 3D Ocean Code

By utilizing the strengths of the Intel Xeon Phi coprocessor, the chapter 3 High Performance Parallelism Pearls authors were able to improve and modernize their code and "achieve great scaling, vectorization, bandwidth utilization and performance/watt". The authors (Jacob Weismann Poulsen, Karthik Raman and Per Berg) note, "The thinking process and techniques used in this … [Read more...]
From ‘Correct’ to ‘Correct & Efficient’: a Hydro2D case study with Godunov’s scheme

Poetically noting that "a rising tide lifts all boats", authors Guillaume Colin de Verdière and Jason D. Sewall demonstrate a 12x increase on Intel Xeon Phi and over 5x increase on Intel Xeon using, "a common set of optimizations [that] benefit both general-purpose Xeon processors and more specialized Xeon Phi accelerators" in chapter 2 of High Performance Parallelism … [Read more...]