
There have been huge advances in DNA sequencing technologies in recent years; e.g. Illumina has just announced the HiSeq X system which can sequence human genomes at a cost of only $1000 per genome. Besides population-scale human genome sequencing another important application of sequencing technologies is environmental sequencing (so called metagenomics). Metagenomic studies … [Read more...]
SPARC64 1 TF/s DP, 2 TF/s SP With 32 Cores And Stacked Memory
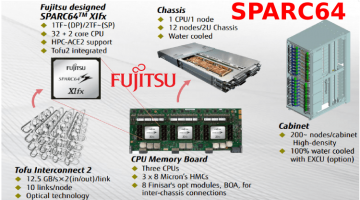
Described as part of Fujitsu's path to exascale, the new Fujitsu SPARC64 enters an enterprise (and HPC) market ripe with ARM64 products quickly coming to market and Intel aggressively working to preserve market share with products such as Intel Xeon Phi and FPGAs stacked on-top of a CPU package. The SPARC64 product looks nice (see infographic below), but key information about … [Read more...]
Nvidia Talks About ARM64 and 64-bit K1 SoC

The Hot Chips 2014 conference conveyed some hot information this week about Nvidia's 64-bit Tegra K1 -the first 64-bit ARM processor for Android devices that pairs the dual-core "Project Denver" CPU with Nvidia's 192-core Kepler GPU (a ceepee geepee). The ARM-based Denver CPU was custom designed by Nvidia and is compatible with ARM's 64-bit ARMv8-A architecture. The chip is … [Read more...]
Commercial OpenCL! SPIR 2.0 Protects IP Yet Allows Powerful, Portable, Source Code Free Kernels

It used to be that portable OpenCL applications required shipping source code for the parallel kernels with the application. In this way, the kernel source code could be compiled for any device at any time in the future. Bad news from an IP protection point of view! The alternative was to pre-compile the kernels thus bloating applications and limiting the devices the OpenCL … [Read more...]
NESAP – The NERSC Exascale Science Application Program – Eight Post-doc Positions to be Filled

DOE’s Office of Science is the single largest supporter of basic research in the physical sciences in the United States, and is working to address some of the most pressing challenges of our time. NERSC is currently hiring eight post-docs to assist this effort. The NESAP program at NERSC addresses the software issues that will arise as scientists adapt their applications to … [Read more...]
WRF Comparison – Neither Phi or NVIDIA M2070 Living Up to Name
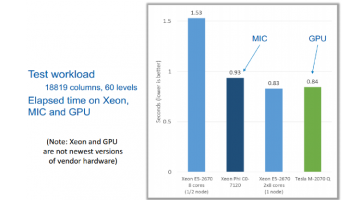
WRF (Weather Research and Forecasting) is an important benchmark for weather modeling, computational scientists, and procurements. WRF is a mesoscale numerical weather prediction system designed to serve both atmospheric research and operational forecasting needs. It allows researchers to generate atmospheric simulations based on real data (observations, analyses) or … [Read more...]
Paper Compares AMD, NVIDIA, Intel Xeon Phi CFD Turbulent Flow Mesh Performance Using OpenMP and OpenCL

Timely for Siggraph 2014 (because animations use meshes) and food-for-thought for CFD (Computational Fluid Dynamics) research, the paper by A. Gorobets, F.X. Trias, R. Borrell, G. Oyarzún and A. Oliva, "Direct Numerical Simulation of Turbulent Flows with Parallel Algorithms for Various Computing Architectures" considers structured and unstructured meshes for incompressible … [Read more...]
Deep-learning Webinar Demonstrates Handwriting Recognition and Efforts to Teach Drone to Fly Down a Wooded Path

Deep-learning is a computational expensive but rewarding method to solve many complex pattern recognition problems. The recent NVIDIA webinar by Dan Claudiu Cireșan, Senior Researcher at the Dalle Molle Institute for Artificial Intelligence (IDSIA) in Switzerland highlighted some of the capabilities of deep-learning for image recognition problems such as handwriting recognition … [Read more...]
SC14 WACCPD Workshop on Accelerator Programming Using Directives

Call For Papers for the SC14 Workshop on Accelerator Programming Using Directives (WACCPD), which brings together leading researchers and software designers at the forefront of the application of high-level directives to program accelerator-based architectures. Using directives improve productivity, and program portability with minimal changes to the applications while … [Read more...]
University of Houston Call To Participate in Oil and Gas Workshop Oct 20

The University of Houston Center for Advanced Computing & Data Systems is reaching out to Oil and Gas domain scientists/researchers who are keen to hear about alternative high-level programming models used to port seismic codes to use accelerators. High-level models such as OpenACC/OpenMP proposes to be more portable and more vendor neutral, and may be complementary to … [Read more...]