
Jim Dempsey bests expert Intel programmers by 40% - 50% simply by using a little bit of ingenuity, along with a slightly different programming technique. He notes that, "a substantial portion of previously lost thread barrier wait time" can be recovered simply by using loosely synchronous (plesiochronous) barriers instead of strictly synchronous barriers. Jim points out that, … [Read more...]
Optimizing for Reacting Navier‐Stokes Equations

Antonio Valles and Weiqun Zhang note the optimizations discussed in their High Performance Parallelism Pearls chapter that, "significantly improved concurrency on both Intel Xeon Phi coprocessors and Intel Xeon processors" by transforming a fine-grain thread parallel approach to a more coarse-grain, memory allocation considerate approach plus improving vectorization. They … [Read more...]
Better Concurrency and SIMD On The HIROMB‐BOOS‐Model (HBM) 3D Ocean Code

By utilizing the strengths of the Intel Xeon Phi coprocessor, the chapter 3 High Performance Parallelism Pearls authors were able to improve and modernize their code and "achieve great scaling, vectorization, bandwidth utilization and performance/watt". The authors (Jacob Weismann Poulsen, Karthik Raman and Per Berg) note, "The thinking process and techniques used in this … [Read more...]
From ‘Correct’ to ‘Correct & Efficient’: a Hydro2D case study with Godunov’s scheme

Poetically noting that "a rising tide lifts all boats", authors Guillaume Colin de Verdière and Jason D. Sewall demonstrate a 12x increase on Intel Xeon Phi and over 5x increase on Intel Xeon using, "a common set of optimizations [that] benefit both general-purpose Xeon processors and more specialized Xeon Phi accelerators" in chapter 2 of High Performance Parallelism … [Read more...]
The Unabridged Chapter 1 Introduction To High Performance Parallelism Pearls

Following is the full, unabridged text of the chapter 1 introduction (written by James Reinders) to High Performance Parallelism Pearls. Thanks to Morgan Kaufmann, James Reinders, and Jim Jeffers for giving permission so TechEnablment can make this available. After reading what James wrote, you will see that summarizing the introduction would simply have left out too much … [Read more...]
Teaching The World About Intel Xeon Phi

The newest book by James Reinders and Jim Jeffers, “High Performance Parallelism Pearls” distills the experience of sixty-nine HPC experts into twenty-eight chapters designed to teach the world about the performance capabilities of the massively-parallel Intel® Xeon Phi™ family of products. Source code for numerous working examples selected for their educational content, … [Read more...]
MSI WS60 Mobile Workstation – Awesome CUDA-Capable, Linux, and Window Mobility

The recently released MSI mobile workstation (WS60 20 OJ 3K-004US) provides a no-compromise laptop for those who wish a thin-and-light desktop replacement at work and when traveling. This device is now my work machine of choice (that relegated a wonderful HP Z800 workstation to a remotely accessed resource). I have found that the WS60 provides a well-designed and … [Read more...]
Programming Deep-learning Neural Networks to Solve Tasks
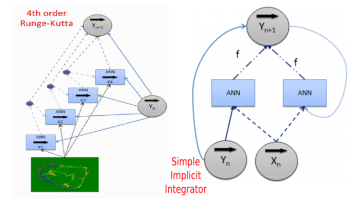
Deep-learning neural networks can be programmed, or structured by a human to perform one or more complex tasks. The key requirements are the ability to (1) design the network topology and (2) lock weights in the ANN (Artificial Neural Network) during training. A powerful example of structured deep-learning comes from the 1993 Farber, et.al. paper, "Identi fication of … [Read more...]
Lustre Delivers 10x the Bandwidth of NFS on Intel Xeon Phi

Lustre on Intel Xeon Phi delivered 10x the bandwidth of NFS as reported in the 2014 Lustre User Group (LUG) presentation "Running Native Lustre* Client inside Intel® Xeon Phi™ coprocessor" by Dmitry Eremin, Zhiqi Tao and Gabriele Paciucci of Intel Corporation. Network file systems are essential to the current generation of Knights Corner Intel Xeon Phi coprocessors because the … [Read more...]
Shared Memory is Simple on Intel Xeon Phi – supports STL!

Shared memory on Intel Xeon Phi, in OpenCL, and CUDA (via managed memory) greatly simplifies programming by eliminating the need to explicitly define all data transfers between host and device memory. Once these implementations mature, it is likely they will become the standard API that programmers use to access data on both Intel Xeon Phi and GPUs. (They also naturally support … [Read more...]