FPGAs, GPUs, and Intel Xeon Phi coprocessors can all offer superb performance at low watt/flop and high flop/dollar ratios for real-time computing. To promote real-time FPGA development, several Altera Engineers (Chee Nouk Phoon,Chei Siang Ng, Steve Jahnke, plus Findlay Shearer, Linux Marketing Manager) examined the impact of operating system jitter on real-time performance in their free whitepaper, “Bare-Metal, RTOS, or Linux? Optimize Real-Time Performance with Altera SoCs“. They tested three configurations including (1) Linux, (2) VxWorks SMP, and (3) a bare-metal RTOS using a application that moves data to the FPGA and found, “Given the complexities of modern applications processors, it is very difficult to create a stable, hand-optimized solution without the use of a modern OS. As shown by the test results in this white paper, even if such a system can be created, it performs no better than an OS-based solution given the system interactions both at the processor level, and with the FPGA.”
Following are the three test setups that perform the operations shown in the image:
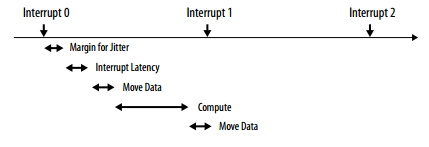
Altera Data mover real-time loop (Image courtesy Altera)
Software Architecture 1: Linux SMP
- Running over Linux in SMP with core affinity mode, on both cores of the dual-A9 cluster
- Core 1: Utilizes the DataMover for data movement and interrupt handling
- Core 0: Idle or busy running a continuous Fibonacci series to simulate non-real-time tasks
- Interrupts are handled in polling or interrupt service routine
Software Architecture 2: VxWorks SMP
- Running over VxWorks in SMP core affinity mode, on both cores of the dual-A9 cluster
- Core 1: Utilizes the DataMover for data movement and interrupt handling
- Core 0: Idle or busy running a continuous Fibonacci series to simulate non-real-time tasks
- Interrupts are handled in polling or interrupt service routine
Software Architecture 3: Bare-Metal Single-Core
- Software Architecture 3: Bare-Metal Single-Core
- Running in bare-metal mode on one core only
- Core 1: Utilizes the DataMover for data movement and interrupt handling
- Core 0: Not utilized to represent a “best case” environment (no overhead or buffer management)
- Interrupts are handled in polling or interrupt service routine
The conclusions in this whitepaper are interesting and imply that moving data to a remote device in a modern Linux OS does not suffer significant performance penalties due to OS jitter. If the analysis is true for FPGA’s, it should also apply to devices such as GPUs and potentially Intel Xeon Phi coprocessors.
A note of caution, the paper “The Case of the Missing Supercomputer Performance” does show that operating system jitter can seriously degrade performance when multiple operating systems are involved in tightly coupled computations.
Leave a Reply