
Release 14.7 of the PGI compiler is now available for download. PGI Accelerator Features and Enhancements Support for CUDA managed data in CUDA Fortran Expanded OpenACC C++ Support Expanded OpenACC Features C global (extern) variables in OpenACC declare directives Fortran module variables in OpenACC declare directives Full support for the atomic … [Read more...]
Beowulf 20 Year Workshop To Also Honour Thomas Sterling

The Center for Research in Extreme Scale Technologies (CREST) at the University of Indiana will organize a workshop to celebrate 20 years of Beowulf and to honour Professor Thomas Sterling for his 65th birthday. The workshop will be held October 13-14, 2014. Visit the 20 Years of Beowulf website to register or learn more. The Beowulf project introduced clusters build from … [Read more...]
SC14 Paid US and Foreign Travel Grants – Deadline Sept. 7

SIGHPC offers travel grants to help undergraduate and graduate students attend the annual SC conference. Who's eligible: Students at the undergraduate or early graduate level, enrolled in an accredited university in any country, and who are members of SIGHPC. Applicants do not have to be making a presentation at SC, but they need to describe why they will benefit from … [Read more...]
Shared Memory is Simple on Intel Xeon Phi – supports STL!

Shared memory on Intel Xeon Phi, in OpenCL, and CUDA (via managed memory) greatly simplifies programming by eliminating the need to explicitly define all data transfers between host and device memory. Once these implementations mature, it is likely they will become the standard API that programmers use to access data on both Intel Xeon Phi and GPUs. (They also naturally support … [Read more...]
Deep-Learning Behind Microsoft Cross-Language Real-Time Skype Translator
Deep-learning lies at the heart of the Microsoft Skype translator, a near real-time speech-to-speech machine translation tool that enables voice conversations between individuals speaking different languages. The claim is that a beta version of Skype Translator will be released sometime in 2014. According to Microsoft, machine-learning of large datasets culled from social … [Read more...]
Intel SPMD Compiler (ISPC) for Xeon and Xeon Phi
When #pragma SIMD is not enough, companies and projects such as Intel, Embree, Dreamworks, Pixar, Autodesk, and SURFsara are looking to the freely available Intel SPMD Program Compiler (ispc) to achieve high vector performance on Xeon and Intel Xeon Phi devices. ISPC is LLVM-based and designed to exploit Intel SIMD architectures … [Read more...]
Robobrain.me

The Cornell Robo Brain (http://robobrain.me) is a large-scale learning system that attempts to learn from publicly available Internet resources, computer simulations, and real-life robot trials. The idea is to associate objects in images with text in order to correlate how they relate to human language, behavior and usage. Applications include prototyping for robotics … [Read more...]
CUDA 340.29 Driver Significantly Boosts GPU Performance (100s GF/s For Machine-Learning)
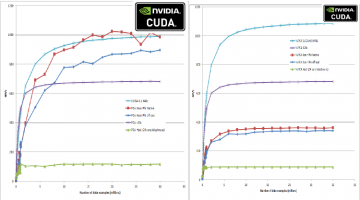
Reports are now coming in about performance boosts that are the result of the CUDA 6.5 production release. The Blender project reports faster rendering time with CUDA-6.5. As can be seen in the graphs below that report performance on the farbopt deep-learning teaching code, CUDA-6.5 with the NVIDIA 340.29 driver have increased performance on linear problems (PCA analysis from … [Read more...]
AAA-Battery Powered Water Splitter Poses Computational Opportunity

Stanford Scientists have developed a water splitter that runs on an ordinary AAA battery and uses commonly available nickel and iron - no exotic materials required! The "save the planet" potential is clearly there as such a low-voltage, low-amperage conversion opens the potential for solar conversion of water to hydrogen. The discovery was made by Stanford graduate student Ming … [Read more...]
A Try-Before-You-Code Linear Regression Method Claims 32% Error Predicting GPU Perf

The paper, "Estimating GPU Speedups for Programs Without Writing a Single Line of GPU Code" by Newsha Ardalani, Karthikeyan Sankaralingam, Xiaojin Zhu at the University of Wisconsin Madison claims a linear regression model can deliver a robust "automated tool that programmers can use to estimate potential GPU speedup before writing any GPU code". According to their study a … [Read more...]