WRF (Weather Research and Forecasting) is an important benchmark for weather modeling, computational scientists, and procurements. WRF is a mesoscale numerical weather prediction system designed to serve both atmospheric research and operational forecasting needs. It allows researchers to generate atmospheric simulations based on real data (observations, analyses) or … [Read more...]
Paper Compares AMD, NVIDIA, Intel Xeon Phi CFD Turbulent Flow Mesh Performance Using OpenMP and OpenCL

Timely for Siggraph 2014 (because animations use meshes) and food-for-thought for CFD (Computational Fluid Dynamics) research, the paper by A. Gorobets, F.X. Trias, R. Borrell, G. Oyarzún and A. Oliva, "Direct Numerical Simulation of Turbulent Flows with Parallel Algorithms for Various Computing Architectures" considers structured and unstructured meshes for incompressible … [Read more...]
Hot At Siggraph 2014 – Multithreading for Visual Effects

The ACM Siggraph conference starts tomorrow, August 10th, in Vancouver, BC. Multithreading for visual effects coupled with massive parallelism has changed the visual effects industry forever. A new book capturing that trend titled, appropriately enough, "Multithreading for Visual Effects", is an excellent source of information about how visual effects are currently performed at … [Read more...]
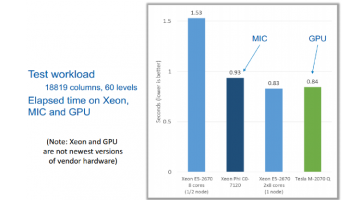
Open Call to Run on the Beacon Intel Xeon Phi System
The National Institute for Computational Sciences (NICS) at the University of Tennessee (UT) is pleased to announce the 2014 open call for participation in the Beacon Project, an ongoing research project funded by the National Science Foundation and UT to explore the impact of emerging computer architectures on computational science and engineering. Beacon is a Cray CS300-AC … [Read more...]
Start Developing on the ARM-Powered NVIDIA SHIELD Tablet Now!

NVIDIA posted a development kit for the NVIDIA Shield Tablet including a banquet of languages (CUDA, Java, C/C++, ...) and developer tools. A complete list of features can be found at Tegra Android Development Pack and are available for download under the NVIDIA GameWorks Download Center. Develop on the latest and fastest mobile hardware available with the all-new NVIDIA® … [Read more...]
Argonne Extreme Training for Exascale Starts Aug 4th Covering OpenACC, OpenMP, MPI, and Vectorization

The Argonne Training Program on Extreme-Scale Computing starts next week. Paul Messina believes more institutions - including universities - need to offer such advanced training. The complexities of exascale computing are the reason as programming the current generation of leadership class machines requires knowledge of a broad spectrum of topics and many skills: both … [Read more...]
SC14 Technical Program and Registration – XSEDE/TACC Resources for Farber Tutorial

Register early for Supercomputing 2014 in New Orleans and save up to $275. View the Technical Program online (and register for our tutorial!) The Technical Program fee includes admission to all conference sessions, exhibits, the Monday night Exhibits opening event, Thursday night event, and one copy of the SC14 proceedings. Click here to view the grid showing access to … [Read more...]
Intel Webinar About “Omni Scale” Next-Generation High-Performance Fabric and Future Directions

Register to attend the August 5th webinar by Joe Yaworski from the Intel Technical Computing Group titled, "High Performance Fabrics from Intel - Today and Tomorrow". Intel's thinking about network infrastructure will have a decided impact on the future of HPC given their recent wins on the NNSA (National Nuclear Safety Agency) 42 PF/s Trinity supercomputer plus the NERSC … [Read more...]
Linus Torvalds Says Fix GCC 4.9 Code Generation!
Phoronix picked up Linus Torvalds' providing some not so gentle feedback on GCC 4.9. GCC 4.9 supports OpenMP 4.0. Apparently the latest GNU compiler is doing some silly spilling of CPU registers (including constants!) that caused a random panic in a load balance function with the in-development Linux 3.16 kernel. On a comparative note, GCC just received … [Read more...]
42 PF/s Trinity Supercomputer to Use Intel Knights Landing

First details on the National Nuclear Security Administration (NNSA) Trinity Supercomputer show that the 42 PF/s system costing $174M USD will run a combination of Intel Haswell and Knights Landing processors. In particular the Intel Xeon Phi devices will use Micron’s Hybrid Memory Cube technology, which will greatly help memory bandwidth and memory capacity limited … [Read more...]