
NVIDIA CEO Jen-Hsun Huang last week hand-delivered an NVIDIA DGX-1 to OpenAI in San Francisco. “I thought it was incredibly appropriate that the world’s first supercomputer dedicated to artificial intelligence would go to the laboratory that was dedicated to open artificial intelligence,” Huang said. OpenAI’s team is working at the cutting-edge of a field that promises … [Read more...]
PGI Compiled OpenACC ILP Loop Beats CUDA-7 by 200 GF/s on Deep-learning PCA Example

The PGI OpenACC compiler beat the performance of a CUDA 7.0 NVIDIA nvcc compiled deep-learning based PCA (Principal Components Analysis) example by 200 GF/s on a K40c using an ILP (Instruction Level Parallelism) loop structure taught in the TechEnablement classes and forthcoming Farber OpenACC book. PCA is an important data analysis tool utilized by data scientists. Sign up for … [Read more...]
CreativeC GPU And Intel Xeon Phi Cluster For SC14 Class Runs Mobile In Van

Our all-day class at SC14 on Sunday November 16, “From ‘Hello World’ to Exascale Using x86, GPUs and Intel Xeon Phi Coprocessors” (tut106s1) received more than double our expected enrollment! Students will be able to run on both Intel Xeon Phi and GPU supercomputers at TACC via an Xsede allocation (thank you very much) and on a CreativeC supercomputer and visualization cluster … [Read more...]
CUDA 340.29 Driver Significantly Boosts GPU Performance (100s GF/s For Machine-Learning)
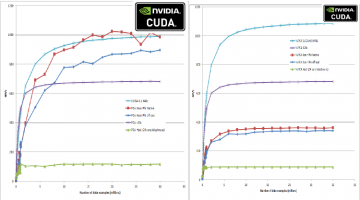
Reports are now coming in about performance boosts that are the result of the CUDA 6.5 production release. The Blender project reports faster rendering time with CUDA-6.5. As can be seen in the graphs below that report performance on the farbopt deep-learning teaching code, CUDA-6.5 with the NVIDIA 340.29 driver have increased performance on linear problems (PCA analysis from … [Read more...]
PyFR: A GPU-Accelerated Next-Generation Computational Fluid Dynamics Python Framework

PyFR is an open-source 5,000 line Python based framework for solving fluid-flow problems that can exploit many-core computing hardware such as GPUs! Computational simulation of fluid flow, often referred to as Computational Fluid Dynamics (CFD), plays an critical role in the aerodynamic design of numerous complex systems, including aircraft, F1 racing cars, and wind turbines. … [Read more...]
Accelerating the Traveling Salesman Problem with GPUs and Intel Xeon Phi
The traveling salesman problem (TSP) is an important computer science optimization problem with numerous real-world applications. There is a huge body of literature on TSP solutions. Following are a few GPU and Intel Xeon Phi accelerated solutions. TSPgpu TSPGPU v2.1 is a GPU-accelerated heuristic solver for the symmetric Traveling Salesman Problem with up to 32767 … [Read more...]
SC14 Technical Program and Registration – XSEDE/TACC Resources for Farber Tutorial

Register early for Supercomputing 2014 in New Orleans and save up to $275. View the Technical Program online (and register for our tutorial!) The Technical Program fee includes admission to all conference sessions, exhibits, the Monday night Exhibits opening event, Thursday night event, and one copy of the SC14 proceedings. Click here to view the grid showing access to … [Read more...]
Part 2: No Idle Time CUDA Task Parallelism Across Eight GPUs

Part 1 in this tutorial series showed that task-based parallelism using concurrent kernels can accelerate applications simply by plugging more GPUs into a system - just as the GPU strong scaling execution model can accelerate applications simply by installing a newer GPU containing more SMX (Streaming Multiprocessors). No recompilation required! NVIDIA nvvp timelines show very … [Read more...]
South Africa Team Wins Their Second Student Supercomputing Competition At ISC14

Congratulations to the South African students who won their second ISC14 Student Supercomputing Competition! In 2013 the South African students were considered the underdog due to their youth and lack of competitive experience. This year the team from the South African Centre for High Performance Computing won the overall 2014 competition. To win, students have to build a … [Read more...]
Farber to Teach All-Day Tutorial At Supercomputing Nov 16 2014

Supercomputing 2014 recently approved my proposal for an all-day class "From 'Hello World' to Exascale Using x86, GPUs and Intel Xeon Phi Coprocessors" (tut106s1), at The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC14). I hope to see you on Sunday November 16, 2014 in New Orleans,! Abstract Both GPUs and Intel Xeon Phi … [Read more...]