Netflix is now streaming the hugely popular Breaking Bad series in 4K Ultra HD resolution. The adoption of 4K content coupled with heavy demand for retina quality displays and long battery life in laptops, tablets and cellphones means that GPU technology companies such as AMD, NVIDIA, Qualcomm, and Intel have a strong incentive … [Read more...]
NVIDIA App Showcase, See What Performance is Possible

Considering utilizing GPUs in your application? The NVIDIA Application Showcase is a great place to examine a broad spectrum of applications that have been GPU accelerated and the speedups that have been achieved. The recently updated list now contains descriptions, links, and performance reports for over 270 GPU accelerated applications. … [Read more...]
EPFL breaks Internet Security Candidate Discrete Logarithms Encryption in Two Hours

It is challenging even for experts to grasp the computational power now available to students and researchers. EPFL researchers decrypted a candidate for the Internet's future security systems based on "discrete logarithms". Allegedly tamper-proof, it could only stand up to the school machines' decryption attempts for two hours. More information: Robert Granger, Thorsten … [Read more...]
May 2014 Current K1 Development Pathways

NVIDIA Tegra K1 Jetson development kits are now available for purchase from Newegg or Microcenter. The NVIDIA Tegra K1 chip has generated much interest due to the CUDA programmability and power efficiency of the ARM/Kepler ceepee-geepee combination. Upcoming Tegra K1 devices include the Xiaomi MiPad, NVIDIA's reference design tablet, plus the K1 powered Shield 2 gaming device. … [Read more...]
Understanding the Rational behind 400 GB Flash-based DIMM Memory

On January 24th, SanDisk announced shipments of ULLtraDIMM SSD storage in concert with an IBM announcement rebranding the SanDisk ULLtraDIMMs as eXFlash DIMMs. On March 21, SanDisk's stocks hit a 14-year high. ULLtraDIMM SSD storage puts Flash memory in a standard DIMM form factor that can be plugged into a memory socket. The Linux, Windows, or VMware UEFI/BIOS … [Read more...]
Run CUDA without Recompilation on x86, AMD GPUs, and Intel Xeon Phi with gpuOcelot
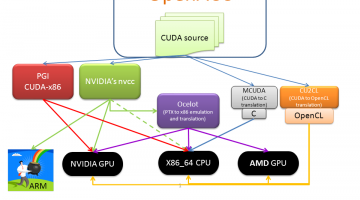
Various pathways exist to run CUDA on a variety of different architectures. The freely available gpuOcelot project is unique in that it currently allows CUDA binaries to run on NVIDIA GPUs, AMD GPUs, x86 and Intel Xeon Phi at full speed without recompilation. It works by dynamically analyzing and recompiling the PTX instructions of the CUDA kernels so they can run on the … [Read more...]
Intel Mobile Reports $929M 1Q14 loss and $3.15B 2013 loss

Mobile is big money unless you are playing catch up. Sean Hollister at The Verge relays a report that the Intel Mobile division lost $3.15 Billion in 2013 and that losses in Q1 2014 are already $929 million. In my article, "Mobile Tech between a Rock and a Hard Place", I noted: Intel’s chief executive Brian Krzanich admitted at the firm’s November 2013 annual investor … [Read more...]
(4/24 update) Signals from Nvidia’s Sumit Gupta

Sumit Gupta is a busy man. Named by HPCwire as a 2013 "Person to Watch", Sumit does not idly take time to create a blog post unless it conveys a message about the NVIDIA Tesla development and marketing effort. His recent blog, "Fostering an Explosion of Innovation in the Data Center", posted by Steve Hamm, recognizes how the data-center is going to be supporting mobile … [Read more...]
Inside NVIDIA’s Unified Memory: Multi-GPU Limitations and the Need for a cudaMadvise API Call

The CUDA 6.0 Unified Memory offers a “single-pointer-to-data” model that is similar to CUDA’s zero-copy mapped memory. Both make it trivially easy for the programmer to access memory on the CPU or GPU, but applications that use mapped memory have to perform a PCI bus transfer occur every time a memory access steps outside of a cache line while a kernel running in a Unified … [Read more...]
Micron’s New Automata Processor

Adding computation to memory is a fantastic way to accelerate applications and real-time solutions. Content addressable memory (CAM) is a widespread and compelling example of how hardware can speed table lookups. (Most virtual memory computers utilize CAM to perform page lookups.) Micron recently announced the Automata Processor (AP) that implements an NFA (Non-deterministic … [Read more...]